前言
CW原理
CW是一种基于优化的攻击,它同时兼顾高攻击准确率和低对抗扰动两个方面。在论文1608.04644 (arxiv.org)中被提出。
在优化过程中需要完成两个目标,一是对抗样本和对应的干净样本的差距应该越小越好;二是对抗样本应该使得模型分类错,且错的那一类的概率越高越好。
最初,CW攻击依赖于对抗性实例的初始表述:
上述公式中的C(x+δ)=t是非线性的,现有的算法难以解决,想要求解需要选择更适合优化的表达式。所以论文作者定义了一系列的目标函数f当且仅当f(x+δ)≤0时,C(x+δ)=t。
所以,优化目标可以修改为如下:
梯度投影下降:
梯度截断下降:这种方法没有真正意义上的截断样本,而是直接把约束加入到了目标函数f中,将f(x+δ)使用f(min(max(x+δ,0),1))来代替,但是这样也存在梯度消失的问题。
变量引入:通过引入变量w使用x+δ满足约束,此时对抗样本就表示为:
$$ x_i + \delta_i = \frac{1}{2}(tan(w_i)+1) \tag{6} $$由于tanh的取值范围为[-1,1],经过这种约束方法,x+δ的取值范围变成了[0,1],很好的满足了上述所提到的要求。 下面就可以开始进行攻击了,在这里主要使用L2范数。此时公式就变为了:$$ minimize \parallel \frac{1}{2}(tanh(w)+1) - x \parallel_2^2 + \; c \; \cdot \; f(\frac{1}{2}(tanh(w)+1)) \\ f(x')=max(max \{ Z(x')_i:i \neq t \}-Z(x')_t, -k) \tag{7} $$此时,令$$ R_n=\frac{1}{2}(tanh(w_n)+1) - X_n \tag{8} $$这里的Rn表示干净样本和对抗样本的差值,这里如果使用tanh,x的范围就是[0,1]。而加入tanh映射空间后,就扩大到了-inf和inf之间。
然后主要说一下目标函数,这里选的是上述论文列出来的第六个。Z(x)代表的就是输入图像还未经过softmax激活函数的向量,这个向量的最大值所对应的标号就是即将被预测的类别。t是希望生成的对抗样本所属于的类别。
max{Z(x’)i,i≠t}表示的就是Z(x)中除去t这个类别以外的最大值,也就是除去t类别以外,最可能将x分类的那个类别的值,将max{Z(x)i,i≠t}-Z(x’)t就是指除去t类别以外最有可能被分类的类别所对应的在未经过softmax激活函数前的向量的最大值和对应t类的的最大值的差。将这个差最小化也就使对抗样本离变成t类越接近。
从(6)可以看到还有一个参数k,这个参数就是置信度。这里可以理解为k越大,置信度越大。k是一个概率,在0~1之间。
为了方便起,对(6)中第一行公式编号为(9),第二行编号为(10),此时:
但是如果f(x’)的值为-k,那么(8)中第二项就变为-ck。k越大,-ck就越小,优化过程就会更倾向于(8)中的第一项,即平方误差那项,就可能会导致生成的对抗样本更接近我们希望它变成的那个类别。
Pytorch实现
这里包含了目标函数f和计算优化目标两部分的内容。
def cw_l2_attack(model, images, labels, targeted=False, c=8, kappa=0, max_iter=1000, learning_rate=0.01):
# 定义目标函数f
def f(x):
# 论文中的 Z(X) 输出 batchsize, num_classes
outputs = model(x)
# 就是一个one-hot编码,然后预测类别为1,其余为0,共有batch_size行,然后每行根据label置为0或1
one_hot_labels = torch.eye(len(outputs[0])).to(device)[labels]
# 1-one_hot_labels就是字面意思,原来是0的,就是1-0=1,原来是1的就是1-1=0,经过处理后除了真实类别以外的都是1
# 水平方向最大的取值,忽略索引。意思是,除去真实标签,看看每个 batchsize 中哪个标签的概率最大,取出概率
# 概率值, 标号
i, _ = torch.max((1 - one_hot_labels) * outputs, dim=1)
# 选择真实标签的概率
j = torch.masked_select(outputs, one_hot_labels.bool())
# 如果有攻击目标,虚假概率减去真实概率,
if targeted:
# 如果 i - j 的计算结果小于 -kappa,那么使用 -kappa 作为结果,而不是原始值。
return torch.clamp(i - j, min=-kappa)
# 没有攻击目标,就让真实的概率小于虚假的概率,逐步降低,也就是最小化这个损失
else:
return torch.clamp(j - i, min=-kappa)
w = torch.zeros_like(images, requires_grad=True).to(device)
optimizer = torch.optim.Adam([w], lr=learning_rate)
prev = 1e10
for step in range(max_iter):
a = 1 / 2 * (nn.Tanh()(w) + 1)
# 最小化目标的两个部分
# 第一个目标,对抗样本与原始样本足够接近
loss1 = nn.MSELoss(reduction='sum')(a, images)
# 第二个目标,误导模型输出
loss2 = torch.sum(c * f(a))
cost = loss1 + loss2
optimizer.zero_grad()
cost.backward()
optimizer.step()
if step % (max_iter // 10) == 0:
if cost > prev:
print('Attack Stopped due to CONVERGENCE....')
return a
prev = cost
attack_images = 1 / 2 * (nn.Tanh()(w) + 1)
return attack_images训练+攻击完整代码
还是和之前一样,使用自己在MNIST手写数据集上训练的LeNet模型来测试CW算法产生的对抗样本。
import torch
import numpy as np
import torchvision
import random
import copy
from tqdm import tqdm
import torch.nn as nn
from torchvision import datasets, transforms
from torchsummary import summary
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torch.utils.data import DataLoader
# 搭建LeNet模型
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 卷积层
self.conv = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# 全连接层
self.fc = nn.Sequential(
nn.Linear(in_features=16 * 5 * 5, out_features=120),
nn.ReLU(),
nn.Linear(in_features=120, out_features=84),
nn.ReLU(),
nn.Linear(in_features=84, out_features=10)
)
def forward(self, img):
img = self.conv(img)
img = img.view(img.size(0), -1)
out = self.fc(img)
# out = self.softmax(out)
return out
net = LeNet()
net = net.to(device)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
mean = 0.1307
std = 0.3801
# 对图像变换
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((mean,), (std,))
]
)# 训练数据集, 测试数据集
train_dataset = datasets.MNIST('../datasets/MNIST', train=True, transform=transform, download=True) # len 60000
test_dataset = datasets.MNIST('../datasets/MNIST', train=False, transform=transform, download=True) # len 10000
# 数据迭代器
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True) # len 938
test_dataloader = DataLoader(test_dataset, batch_size=64, shuffle=True) # len 157
lr = 1e-3
epochs = 20
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', factor=0.5, verbose=True, patience=5, min_lr=0.0000001)train_loss = []
train_acc = []
val_loss = []
val_acc = []
for epoch in tqdm(range(epochs)):
train_losses = 0
train_acces = 0
val_losses = 0
val_acces = 0
for x, y in train_dataloader:
x, y = x.to(device), y.to(device)
output = net(x)
# 计算loss
loss = criterion(output, y)
# 计算预测值
_, pred = torch.max(output, axis=1)
# 计算acc
acc = torch.sum(y == pred) / output.shape[0]
# 反向传播
# 梯度清零
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_losses += loss.item()
train_acces += acc.item()
train_loss.append(train_losses / len(train_dataloader))
train_acc.append(train_acces / len(train_dataloader))
# 模型评估
net.eval()
with torch.no_grad():
for x, y in test_dataloader:
x, y = x.to(device), y.to(device)
output = net(x)
loss = criterion(output, y)
scheduler.step(loss)
_, pred = torch.max(output, axis=1)
acc = torch.sum(y == pred) / output.shape[0]
val_losses += loss.item()
val_acces += acc.item()
val_loss.append(val_losses / len(test_dataloader))
val_acc.append(val_acces / len(test_dataloader))
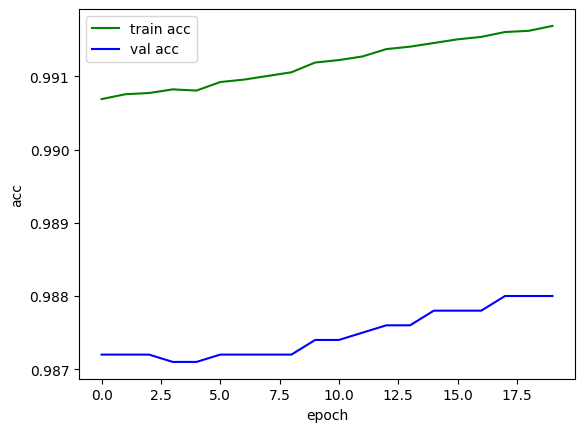
print(f"epoch:{epoch+1} train_loss:{train_losses / len(train_dataloader):.4f}, train_acc:{train_acces / len(train_dataloader):.4f}, val_loss:{val_losses / len(test_dataloader):.4f}, val_acc:{val_acces / len(test_dataloader)}")
plt.plot(train_loss, color='green', label='train loss')
plt.plot(val_loss, color='blue', label='val loss')
plt.legend()
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()
plt.plot(train_acc, color='green', label='train acc')
plt.plot(val_acc, color='blue', label='val acc')
plt.legend()
plt.xlabel("epoch")
plt.ylabel("acc")
plt.show()
PATH = './cw_mnist_lenet1.pth'
torch.save(net, PATH)5%|▌ | 1/20 [00:08<02:46, 8.76s/it]
epoch:1 train_loss:0.0304, train_acc:0.9907, val_loss:0.0406, val_acc:0.9872
10%|█ | 2/20 [00:18<02:50, 9.49s/it]
epoch:2 train_loss:0.0301, train_acc:0.9908, val_loss:0.0404, val_acc:0.9872
15%|█▌ | 3/20 [00:28<02:44, 9.70s/it]
epoch:3 train_loss:0.0300, train_acc:0.9908, val_loss:0.0403, val_acc:0.9872
20%|██ | 4/20 [00:37<02:29, 9.37s/it]
epoch:4 train_loss:0.0298, train_acc:0.9908, val_loss:0.0401, val_acc:0.9871
25%|██▌ | 5/20 [00:48<02:26, 9.79s/it]
epoch:5 train_loss:0.0296, train_acc:0.9908, val_loss:0.0399, val_acc:0.9871
30%|███ | 6/20 [00:58<02:19, 9.97s/it]
epoch:6 train_loss:0.0294, train_acc:0.9909, val_loss:0.0398, val_acc:0.9872
35%|███▌ | 7/20 [01:07<02:04, 9.57s/it]
epoch:7 train_loss:0.0293, train_acc:0.9910, val_loss:0.0396, val_acc:0.9872
40%|████ | 8/20 [01:17<01:57, 9.78s/it]
epoch:8 train_loss:0.0291, train_acc:0.9910, val_loss:0.0395, val_acc:0.9872
45%|████▌ | 9/20 [01:28<01:50, 10.06s/it]
epoch:9 train_loss:0.0290, train_acc:0.9911, val_loss:0.0393, val_acc:0.9872
50%|█████ | 10/20 [01:36<01:36, 9.68s/it]
epoch:10 train_loss:0.0288, train_acc:0.9912, val_loss:0.0392, val_acc:0.9874
55%|█████▌ | 11/20 [01:46<01:27, 9.78s/it]
epoch:11 train_loss:0.0287, train_acc:0.9912, val_loss:0.0390, val_acc:0.9874
60%|██████ | 12/20 [01:57<01:19, 9.94s/it]
epoch:12 train_loss:0.0286, train_acc:0.9913, val_loss:0.0389, val_acc:0.9875
65%|██████▌ | 13/20 [02:05<01:07, 9.58s/it]
epoch:13 train_loss:0.0285, train_acc:0.9914, val_loss:0.0388, val_acc:0.9876
70%|███████ | 14/20 [02:16<00:58, 9.80s/it]
epoch:14 train_loss:0.0283, train_acc:0.9914, val_loss:0.0387, val_acc:0.9876
75%|███████▌ | 15/20 [02:26<00:49, 10.00s/it]
epoch:15 train_loss:0.0282, train_acc:0.9915, val_loss:0.0386, val_acc:0.9878
80%|████████ | 16/20 [02:37<00:40, 10.09s/it]
epoch:16 train_loss:0.0281, train_acc:0.9915, val_loss:0.0384, val_acc:0.9878
85%|████████▌ | 17/20 [02:47<00:30, 10.21s/it]
epoch:17 train_loss:0.0280, train_acc:0.9915, val_loss:0.0383, val_acc:0.9878
90%|█████████ | 18/20 [02:56<00:19, 9.75s/it]
epoch:18 train_loss:0.0279, train_acc:0.9916, val_loss:0.0382, val_acc:0.988
95%|█████████▌| 19/20 [03:06<00:09, 9.93s/it]
epoch:19 train_loss:0.0278, train_acc:0.9916, val_loss:0.0381, val_acc:0.988
100%|██████████| 20/20 [03:16<00:00, 9.84s/it]
epoch:20 train_loss:0.0277, train_acc:0.9917, val_loss:0.0380, val_acc:0.988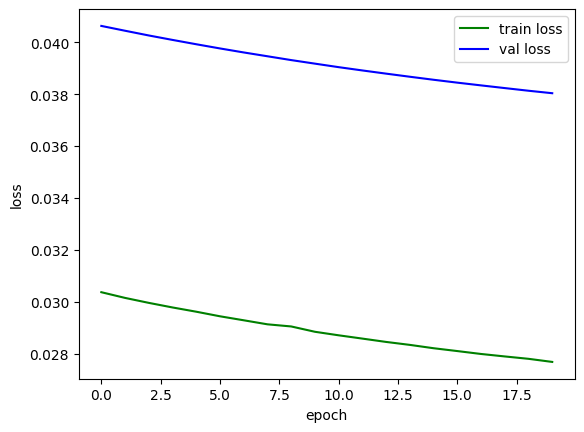
这里没有改变参数,只是对一个参数进行了测试
# 用于可视化
adv_examples = []
correct = 0
vis_max = 10
vis_num = 0
rand_num = -1
for data, label in test_dataloader:
data, label = data.to(device), label.to(device)
attack_data = cw_l2_attack(model=net, images=data, labels=label)
output = net(attack_data)
_, pred = torch.max(output, axis=1)
# print(label)
# print(pred)
# print(sum(pred == label))
# 统计一下攻击以后正确的数量
correct += torch.sum(pred == label)
rand_num = torch.randint(0, 11, (1,))
if rand_num % 2 == 0 and vis_num < vis_max:
adv_examples.append((data, label, attack_data, pred))
vis_num += 1
print("Attack accuracy:", float(correct) / len(test_dataset))可视化生成的对抗样本
plt.figure(figsize=(12, 15))
index = 0
# 当前行画的图片
current = 0
# 设置当前行画原始还是攻击
odd = 0
for i in range(len(adv_examples)):
data, label, attack_data, pred = adv_examples[i]
current = 0
for j in range(len(adv_examples[i][1])):
# 一个批次的数据只画5张
if label[j] != pred[j] and current < 5:
index += 1
current += 1
plt.subplot(len(adv_examples), 5, index)
if current == 1 and odd % 2 == 0:
plt.ylabel("original image")
elif current == 1 and odd % 2 == 1:
plt.ylabel("attack image")
if odd % 2 == 1:
print()
plt.title("{} --> {}".format(label[j], pred[j]))
plt.imshow(attack_data[j][0].cpu().detach().numpy())
else:
plt.title("{} --> {}".format(label[j], label[j]))
plt.imshow(data[j][0].cpu().detach().numpy())
odd += 1
plt.tight_layout()需要注意的是,这篇文章中的可视化,我尝试了batch_size不为1,而是64,和前几篇文章截然不同。

参考文献
独家解读 | 基于优化的对抗攻击:CW攻击的原理详解与代码解读-腾讯云开发者社区-腾讯云 (tencent.com)
对抗攻击篇:CW 攻击算法 | Just for Life. (muyuuuu.github.io)
对抗样本之CW原理&coding_cw对抗样本-CSDN博客(对CW算法的手稿理解,很清晰!!!)
5.基于优化的攻击——CW - 机器学习安全小白 - 博客园 (cnblogs.com)
CW对抗样本生成算法 torch实现_cw对抗样本生成方法是ifgsm吗-CSDN博客(对置信度k的举例解释)
