GAN网络
生成对抗网络(GAN,Generative adversarial network)是一种深度学习网络,他的灵感来自与零和博弈思想。GAN其实是由两个神经网络组成,分别是生成网络Generator(下文简称为G)和判别网络Discriminator(下文简称为D)。
生成网络G用于生成模拟数据,判别网络D用于判别生成的数据是真是假,通过两个网络的博弈,不断使生成网络的生成数据更加逼真,导致判别网络无法判别真假,使判别网络的判断也要更加准确。这二者相互博弈,所以运用的是零和博弈思想,并且叫做生成对抗网络。
在一篇文章中看到作者这样比喻GAN网络。将小偷比作生成网络,警察比作判别网络。小偷只有伪装的不像小偷才能不被警察发现。最初小偷伪装的很差,总被警察发现,所以小偷不断提升自己,被警察抓住的几率变小一些,而警察发现小偷伪装技术变强也不断提高自己的业务能力。就这样,小偷和警察不断对抗提升自己,最后成为了伪装技术高超的小偷和抓捕技术高超的警察。
GAN网络基本结构
我在网上找到这么一张图片,形象的展示了GAN的架构。
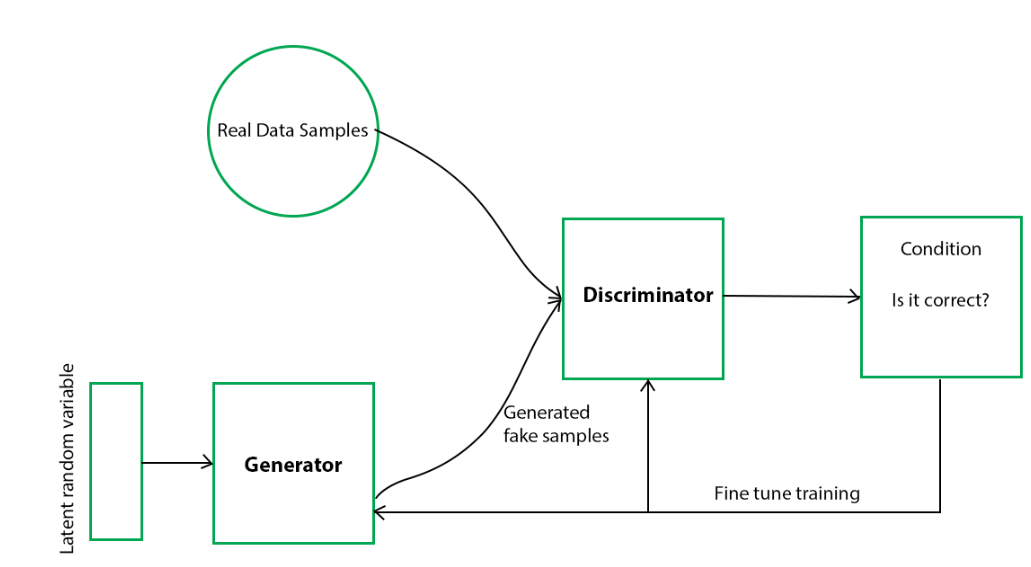
接下来自己介绍一下生成网络和判别网络。
生成网络Generator
生成网络的输入是随机数据(噪声),输出是一幅图像,往往是假图像。生成网络的模型结构可以随意,可以是简单的多层全连接神经网络,也可以是反卷积网络等。我们可以认为生成网络的输入包含着输出所要携带的信息,以MNIST手写数据集为例,输入可以表明了输出的数字为几,模糊程度等内容,因为这里对其具体信息不做要求,只希望能最大程度地骗过判别器,所以输入最好是可以满足常见分布的数据。
判别网络Discriminator
判别网络顾名思义其作用就是进行判别。判别网络的输入既有真实图片,也有生成网络生成的假图片。判别网络的输出会是一个概率,来说明输入的图像是真实图片还是假图片,而不是判别输入图像的类别是什么,是一个二分类问题。仍然以MNIST手写数据集为例,判别网络不是判别输入的图像是数字几,而是判定这副图像是不是由生成网络产生。和生成网络一样,判别网络的模型结构可以是多层全连接网络,也可以是卷积神经网络等。
GAN网络优化
我们根据上文已经知道了GAN中包含两个网络,这两个网络的作用不同,所以这两个网络的优化目标就不同,自然其损失函数也是不相同的。
首先看生成网络的损失函数:
接下来看判别网络的损失函数:
GAN网络训练
知道了GAN网络的优化目标,接下来看一下GAN网络的训练过程。
GAN网络采用的是交替训练的策略。
也就是首先固定一个网络,训练另一个网络,两者交替的进行。我们默认真实图片的标签为1,假图片的标签为0。
对于判别网络的训练,让真实图片和假图片经过判别网络,然后计算和各自对应标签的损失就可以了。
对于生成网络的训练,令生成网络产生的假图片,并通过判别网络,计算判别网络输出的概率值与label为1的距离。
PyTorch代码
import os
import torch.autograd
import torch.nn as nn
import numpy as np
import random
from torch.autograd import Variable
from torchvision import transforms
from torchvision import datasets
from torchvision.utils import save_image
import matplotlib.pyplot as plt
# 定义一个规范化图像的函数
def to_img(x):
out = 0.5 * (1 + x)
out = out.clamp(0, 1)
out = out.view(-1, 1, 28, 28)
return out
# 参数设置
batch_size = 128
num_epoch = 150
z_dimension = 100
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载数据
mnist = datasets.MNIST(root='./dataset/', train=True, transform=img_transform, download=True)
dataloader = torch.utils.data.DataLoader(dataset=mnist, batch_size=batch_size, shuffle=True)接下来定义判别网络和生成网络,网络主题结构就采用几层全连接层。
# 定义判别器Discriminator
class Discriminator(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.dis = nn.Sequential(
nn.Linear(784, 256),
nn.LeakyReLU(),
nn.Linear(256, 128),
nn.LeakyReLU(),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.dis(x)
return x # 定义生成器Generator
class Generator(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.gen = nn.Sequential(
nn.Linear(100, 256),
nn.LeakyReLU(),
nn.Linear(256, 512),
nn.LeakyReLU(),
nn.Linear(512, 784),
nn.Tanh()
)
def forward(self, x):
x = self.gen(x)
return xD = Discriminator()
G = Generator()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if torch.cuda.is_available():
D = D.to(device)
G = G.to(device)
# 定义损失函数,优化器
criterion = nn.BCELoss() # 二分类的交叉熵
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0003)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0003)最后就是对GAN的训练。
d_loss_list = []
g_loss_list = []
for epoch in range(num_epoch):
# 不要图片的标签
for i, (img, _) in enumerate(dataloader):
# 获取batchsize
num_img = img.size(0)
# 转换为(batchsize, 784)
img = img.view(num_img, -1)
real_img = img.to(device) # shape: [128, 784]
real_label = torch.ones(num_img).to(device)
fake_label = torch.zeros(num_img).to(device)
# 判别器Discrimination训练
# 真的图片判别为真,假图片判别为假
real_out = D(real_img) # shape: [128, 1]
real_out = real_out.squeeze() # shape: [128,]
# 真实图片的Loss
d_loss_real = criterion(real_out, real_label)
# 真实图片的判别值,越接近1越好
real_scores = real_out
# 计算假图片的损失
# 随机生成一些噪声
z = torch.randn(num_img, z_dimension).to(device) # shape: [128, 100]
# 将噪声通过生成网络,生成假图片,避免梯度传到G中,因为G不需要更新(此时训练D)
fake_img = G(z).detach()
# 判别器判别假图片
fake_out = D(fake_img) # shape: [128, 1]
fake_out = fake_out.squeeze() # shape: [128,]
# 计算假图片的loss
d_loss_fake = criterion(fake_out, fake_label)
# 假图片的判别值,越接近0越好
fake_scores = fake_out
# 损失函数和优化
# 损失包括真损失和假损失
d_loss = d_loss_fake + d_loss_real
# 梯度清零
d_optimizer.zero_grad()
# 反向传播
d_loss.backward()
# 前向传播
d_optimizer.step()
# 生成器Generator训练
# 希望生成的假的图片被判别器识别为真的图片
# 将判别器固定,将假图片传入判别器的结果与真实label对应
# 方向传播更新生成网络里的参数
z = torch.randn(num_img, z_dimension).to(device)
# 得到假图片
fake_img = G(z)
# 将假图片经过判别器得到的结果
output = D(fake_img) # shape: [128, 1]
output = output.squeeze()
# 将假图片与真实图片的label计算loss
g_loss= criterion(output, real_label)
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
d_loss_list.append(d_loss.data.item())
g_loss_list.append(g_loss.data.item())
print('Epoch[{}/{}],d_loss:{:.6f},g_loss:{:.6f} '
'D_real_output: {:.6f},D_fake_output: {:.6f}'.format(
epoch+1, num_epoch, d_loss.data.item(), g_loss.data.item(),
real_scores.data.mean(), fake_scores.data.mean() # 打印的是真实图片的损失均值
))
if epoch == 0:
real_images = to_img(real_img.cpu().data)
save_image(real_images, './img/real_images.png')
elif epoch % 10 == 0:
fake_images = to_img(fake_img.cpu().data)
save_image(fake_images, './img/fake_images-{}.png'.format(epoch + 1))由于能力有限,代码参考了参考文献中的第五篇文章。并在其基础中将一些pytorch中已经弃用的函数进行了修改。并在其他地方进行了小部分调整。
看看生成的图像,这是原图。

这是训练10轮后的图像
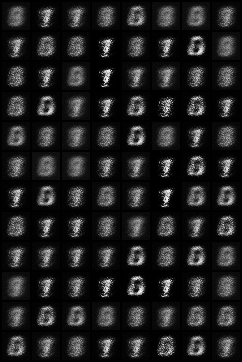
这是训练50轮后的图像
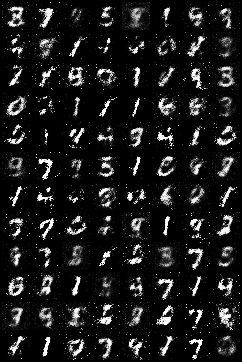
这是训练140轮后的图像
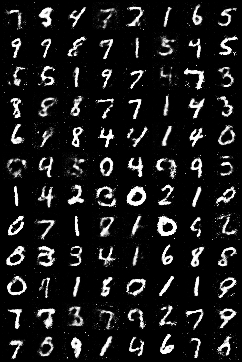
参考文献
一文看懂「生成对抗网络 - GAN」基本原理+10种典型算法+13种应用 (easyai.tech)
深度学习:GAN 对抗网络原理详细解析(零基础必看)_gan网络-CSDN博客
深度学习—-GAN(生成对抗神经网络)原理解析_gan神经网络-CSDN博客
