前言
最近在看一些few shot的文章时,发现将target和query作为q和kv以及kv和q会取得完全不同的效果。
为了加深自己对transformer的理解,所以决定阅读https://www.cnblogs.com/rossiXYZ/p/18785601中的文章并进行思考,并在这里记录阅读过程中的所思所想,并对作者的观点进行归纳总结,供自己日后阅读。
Transformer
注意力机制
对于transformer的产生背景:对于文本生成任务来说,自回归模型 –> 隐变量自回归模型 –> 编码器-解码器模型
从宏观角度来看,文本生成任务就是通过总结上文,来对下文进行预测,但是怎么对长文本的序列压缩到一个较小状态值得考虑。人们使用神经网络进行拟合,即CNN,RNN和Transformer。
对于序列转换任务来说面临着两个挑战:对齐和长依赖。
对齐:英文单词和中文翻译必然不是一对一的关系,这就会导致我们在时刻t,无法确定此时模型是否已经获得了输出正确结果所需要的所有信息。所以人们通过将上文信息编码成为隐状态,这能够保证模型接受所有信息,但是,解码时无法确认每个词之间的贡献度,而是将其默认看作贡献度是一致的。
长依赖:作者在文章中举了一个例子”秋蝉的衰弱的残声,更是北国的特产,因为北平处处全长着树,屋子又低,所以无论在什么地方,都听得见它们的啼唱。”从这个句子中,我们可以看出”它们”是指代”秋蝉”,而模型则需要依赖交互关系建模,神经网络很难处理这里依赖关系,尤其是随着两个位置之间间隔越长,这种依赖越难学习,从而导致长时信息丢失,也就是遗忘问题。
对于CNN来说,众所周知,其通过卷积核去捕获空间中的局部依赖关系,但是由于卷积核的尺寸是有限的,并且CNN对相对位置比较敏感,而对绝对位置不敏感,所以其很难提取长距离依赖关系。人们则是通过堆叠更深的卷积去将局部感受野扩大,不同深度的所看到的内容范围不同,在最顶层的卷积理论上是被看作将所有的序列信息压缩到了一个卷积窗口中的。但是这种逐深的去传播往往会导致信息只有部分被保留下来,导致模型性能下降。所以通常不会使用CNN去处理长文本信息。
(我自己在读论文的过程中,其实经常可以看到Transformer+CNN这两种结构结合的模型,其立意通常就是Transformer去捕获长程依赖,而CNN去捕获局部信息,两种互相增强。)
对于RNN来说,其本身就是一种时序结构,后面的时刻天然的就依赖于前一时刻的输出。其记忆功能,又使得它能够记住之前时刻的信息。所以在理论上,RNN可以利用先前的信息去预测无限长的文本。RNN在处理序列时也使用了权重共享的策略,这可以减少模型的参数量,但是也埋下了雷。在RNN中,其使用同一个函数将上文压缩成固定长度的隐向量,依赖这个固定长度的隐向量去预测下文毫无疑问会造成信息遗失的问题。很简单,因为长度固定,当信息越多,其丢失的细节一定也会更多,所以RNN中的隐向量对于编码上文的细节能力在本质上是有限的。同样地,在预测过程中,权重共享会导致对输入单词赋予相同权重,这显然无法区分其重要程度。对于RNN中的信息遗失问题,如果关键信息出现的序列起点,那么就很容易被忽略,并且其会优先关注尾部的输入,这其实也导致了难以捕获长距离依赖关系,这也让RNN形成一种有序假设,会让其无法平带看待每个输入的顺序。此外,RNN依赖先前隐状态和当前输入,导致其无法并行,训练效率极低,并且其信息传输通路只有一条,那么随着时间步的增加,其在反向传播时一定会导致指数级的衰减或爆炸。当提取消失时,信息无法及时传递,导致RNN难以学习长距离依赖关系,当梯度爆炸时,又会导致网络不稳定。
综上所述,RNN和CNN都无法解决上面所提到的两个问题–对齐和长依赖。
注意力机制本质上就是要像人类一样进行感知,可以选择性地优先关注相关信息,忽略或者抑制不相关信息。
注意力机制本质是上下文决定一切,注意力机制是一种资源分配方案,注意力机制是信息交换,是”全局信息查询”
论文”A General Survey on Attention Mechanisms in Deep Learning”中给出了注意力模型的通用结构,并将其称作任务模型。
任务模型中包括四个部分:
- 特征模型:特征模型就是将任务模型的输入X转换为特征向量F;
- 查询模型: 查询模型产生查询向量q,q就可以理解为哪个特征向量中包含对q最重要的信息;
- 注意力模型:注意力模型会输出上下文向量c,其输入是特征向量F和查询向量q
- 在注意力模型中,从输入特征向量F生成Key和Value;
- 利用q和Key计算相似度分数,产生相似度向量e, $ e_l $ ** 就代表Key中第l列对q的重要性。**
- 对相似度分数进行处理得到注意力权重a;
- 利用权重a对Value进行计算,得到上下文向量c
- 输出模型: 利用上下文向量c将各个部分进行加权。
注意力模型中不可避免的要提到QKV这三个关键术语,对于注意力模型中的两个输入q和F,可以将其理解为q(正在处理的序列/目标序列)和F(被关注的序列/源序列)
- Q 查询矩阵:其针对目标序列q,可以理解为某个单词向其它单词发出询问,目标序列中的每个元素把自己的特征总结到一个向量query中(我理解为线性映射变为query),所有元素的query就共同构成了查询矩阵Q;
- K 键矩阵:其针对源序列F,可以理解为某个单词依据自身特征对查询单词的回答,同理,源序列中的每个元素将自己的特征总结到一个向量key中,所有元素的key就共同构成了键矩阵K;
- V 值矩阵:其针对源序列F,每个元素的实际值是向量value,所有元素的value就构成了值矩阵V。
实际中,我们的KV是来自同一个特征,但是千万不能将其视作相同,K和V分别代表着不同的含义,而这个含义就是通过线性投影去映射出来的。
我对QKV的理解就把Q当作一个询问者,询问我和谁像,而K只是用来计算与Q是否像,V则是用于被取出,其对应的就是QK算出来像所对应的值
作者给出一种比喻:query是你要找的内容,key是字典的索引(字典里面有什么样的信息),value是对应的信息。普通的字典查找是精确匹配,即依据匹配的键来返回其对应的值。而注意力机制是向量化+模糊匹配+信息合并。注意力机制不仅查找最佳匹配,还要依据匹配程度做加权求和。源序列每个元素转化为<key,value>对,这就构成了源序列的字典。目标序列每个元素提出了query,这就是要查询的内容。在查找中,目标序列中每个元素会用自己的query去和目标序列每个元素的key计算得到对齐系数。这个对齐系数就是元素之间的相似度或者相关性。query和key越相似就代表value对query的影响力越大,query越需要吸收value的信息。随后query会根据两个词之间的亲密关系来决定从V中提取出多少信息出来融入到自身。
我认为注意力机制中比较重要的一点就是在解码过程中,会计算与每一个输入部分进行计算,其并不是像RNN存储一个包含上文信息的固定长度的隐状态,而是存储每个上文信息的隐状态,这使每个输入的隐状态没有被压缩,并且也忽略了距离的影响。
对于注意力中的加权求和,可以拆分成两部分:加权和求和:
- 加权:CNN和RNN的权重会被固定,在测试阶段使用固定的权重,而注意力机制则是会动态地计算当前应该关注哪些输入
- 求和:对数据进行融合,不是按同等贡献,而是依据相似度有侧重点的进行融合。
对比注意力机制和CNN,RNN,不难看出:
- 对齐:注意力机制中允许对输入的不同部分计算相关性,这使不同输入与输出的对齐得到了控制,而不再是同等的对齐贡献
- 长距离依赖:注意力机制中存储了每个输入的隐状态,这就避免了头部信息随着时间序列的增大而消失,并且消除了距离的概念,使RNN中的有序被克服,Transformer可以平等地看待每一个输入的隐状态。
虽然注意力机制可以很好的克服CNN和RNN的缺陷,但是内存以及算例的需求也是急剧增长。
总结架构
在介绍Transformer中,这里再次对一些关键的术语进行解释:
分词(tokenize): 分词就是将用户输入的文本(通常是连续的文字)拆解为若干个独立的词汇单元,即一个一个的token;
编码:在NLP中会有一个词表,这些词表与词之间是一一对应的关系,其会为对应的词分配一个独一无二的整数ID代表词表的索引;
嵌入化(embedding): embedding就是将分词通过编码转化成的数字映射到一个高维向量空间中,这个token就被转换为了word embedding,只有这样每个token才能被LLM处理。embedding过程也可以被分为两部分:
- 生成每个token的embedding,其堆叠在一起形成一个embedding矩阵,该矩阵是一个可学习的,通过随机初始化获得;
- token embedding则是将每个token得到的整数ID和一个高维向量相关联,其会去embedding矩阵中查找第token_id的数据作为embedding.
- 生成每个token的embedding,其堆叠在一起形成一个embedding矩阵,该矩阵是一个可学习的,通过随机初始化获得;
位置编码: 对于文本来说, 模型不单单需要理解文本的语义,还需要知道文本中每个单词的顺序,位置编码可以确保单词的顺序不会丢失,契合embedding向量相加,形成最终的嵌入矩阵.
可以结合下图去理解相关操作: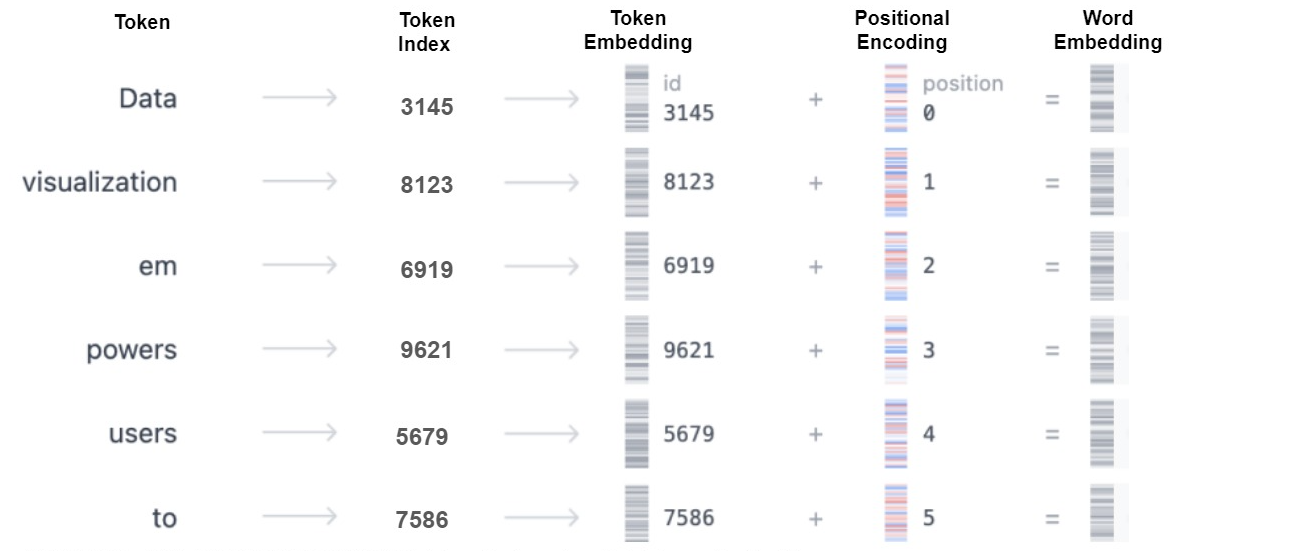
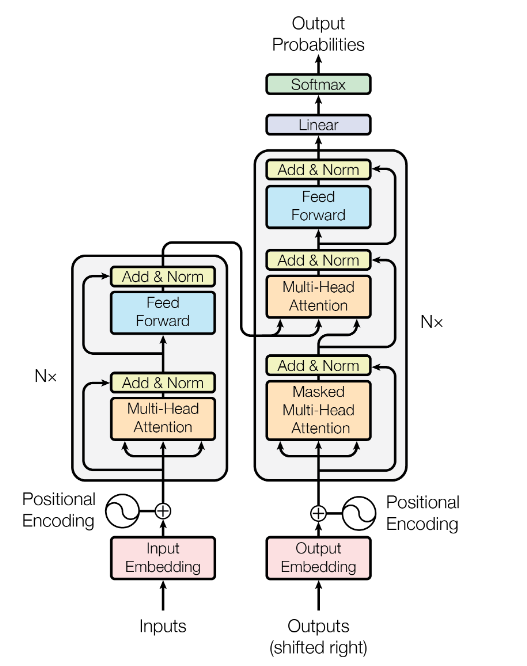
这是Transformer论文中的架构图, 其很明显可以分为四部分:输入,输出,编码器(Encoder, 左部分)和解码器(Decoder, 右部分). 从图中可以看出,编码器和解码器部分都有$ \times N $ 这表示这部分会堆叠N次,这种将同一结构重复多次的分层机制就是栈. 这里对分层做一个简短的解释,即第i层的输出会被作为第i+1的输入,以此不断重复N次$ (i\in {1, N-1}) $.
此外,从图中也可以看到解码器的输入其实是有两个:
- 编码器的输出,其将inputs编码成了隐状态(对应于RNN中的hidden state, Transformer中也叫memory), 或者也可以理解为编码器把源语言的完整句子编码成为隐状态,并一次性输出给解码器;
- Ouputs(shifted right):这个输入位于图的右下角,Outputs实际上是解码器之前输出的拼接,因为解码器不能一次性输出生成的文本,其也是一个一个输出,所以这次的输出需要加到这次输入的后面作为下次的输入,shifted right的目的也就是将序列整体右移一位.
作者在这里提到了对多层的理解,自己之前只是也多层理解成为对捕获到的信息重复精炼,并没有再往深处思考,文中作者给出了几个观点:
- BERT中短语表示主要在神经网络的较低层捕捉短语级别的信息,并在中间层中编码了语言要素的复杂层次结构。这个层次结构以表层特征作为基础,中间层提取语法特征,最上层呈现语义特征。(论文: What Does BERT Learn about the Structure of Language?)
- 较深层的注意力模块(最后25%的层)主要负责记忆, 较浅层的注意力模块对模型的泛化和推理能力至关重要, 在深层注意力模块应用短路(short-circuit)干预可以显著降低记忆所需内存,同时保持模型性能(这里其实也说明了残差连接的重要性).(论文: Analyzing Memorization in Large Language Models through the Lens of Model Attribution)
- 语言模型存在一种普遍机制:防止过度自信(anti-overconfidence):在模型的最后若干层,语言模型总是在抑制正确答案的输出。这种抑制具体又分为两种:1. 通过注意力头将输入起始位置的信息复制到了最末位置,我们发现起始位置的信息似乎包含了很多高频的token,模型可以通过这种方法来让高频token稀释残差流中的正确回答,降低回答的自信度; 2. 末层的MLP似乎在将残差流引导向一个“平均”token的方向(平均token是基于训练数据的词频,对token embedding加权平均得到的结果)。论文(Interpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models)
Transformer中有三种注意力结构:
自注意力(Encoder中): 处理单个序列内部元素之间的关系;
交叉注意力:(Decoder中) 处理两个不同的序列之间的关系;
掩码自注意力(因果自注意力,Decoder中): 通过掩码去控制模型在计算注意力分数时的关注范围, 从而在解码时不会受到未来信息的影响.(比如一个完整的句子为: 你今天学习自注意力机制了嘛?,当我们处理到”学”时,我们只能利用”你今天”,而”习自注意力机制了嘛”这些信息是不能看到的,因为这是我们之后要预测的内容) . 引入掩码的原因: Transformer是自回归模型, 当当前输出文本加入到输入序列就会变成新的输入, 后续的输出依赖于前面的输出词,这种特性使其具备因果关系. 这种串行结构显然会大幅影响训练时间,所以人们通过引入掩码,这样在计算注意力的时候通过掩码以确保后面的词不会参与前面词的计算.
在Transformer的原论文种,作者就指出如果没有skip-connection和MLP,那么自注意力网络的输出会朝着一个rank-1的矩阵收缩, 这说明skip-connection和MLP可以很好地阻止自注意力网络的这种”秩坍塌”
