前言
这篇论文很久之前就看过一次,但当时也没有看太懂,正好最近在看Transformer的相关内容,所以就翻出来再读一遍。对部分内容做一个记录。本文内容为个人理解,如有错误,欢迎指正。
原文链接:[2208.13721] CounTR: Transformer-based Generalised Visual Counting
代码链接:Verg-Avesta/CounTR: CounTR: Transformer-based Generalised Visual Counting
我对论文进行了复现,然后代码中有些可能与现版本不兼容的内容进行了修改,同时对源码增加了中文注释,放在github,链接为:https://github.com/LengNian/PaperRecurrent/tree/main/CounTR--Transformer-based Generalised Visual Counting(不要点链接,复制到浏览器)
本文需要用到的权重文件,可以在作者的Readme文件中找到。
论文内容
两阶段训练
本文采用一种两阶段的训练方式,即现在FSC147训练集上进行预训练,然后在下游任务上进行微调。
预训练
预训练过程中使用MAE自监督训练,首先将输入图像分成不重叠的patch作为模型的输入,加入位置编码以后进行一个随机掩码,用于遮挡输入图像并送入编码器,然后通过解码器图像,得到对patch的恢复。然后通过计算恢复图像和原始图像的损失,来调整参数优化模型。
微调阶段
在微调阶段,会用预训练的权重初始化图像的编码器,然后对模型再进行微调。该阶段使用的模型如图所示。
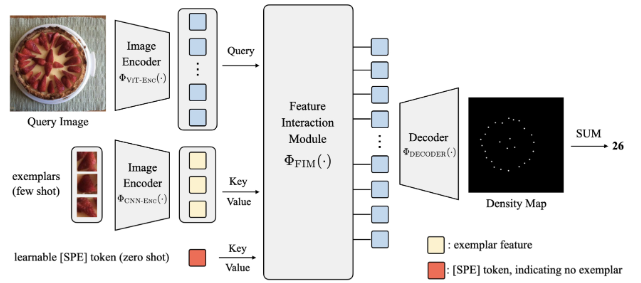
作者将查询图像和示例图像都进行编码,查询图像编码器采用12层Transformer中的编码层$ \Phi_{VIT-ENC}$,该编码器采用Cross VIT网络。示例图像的编码器$ \Phi_{CNN-ENC}$用卷积层和全局池化层的组合。经过编码器后将查询图像编码后的的向量作为Query,示例图像编码后的向量作为Key和value送入到特征交互模块$\Phi_{FIM}$。特征交互模块由TYransformer的解码层构成。
解码器$\Phi_{DECODER}$使用一种渐进的上采样设计方法,一工会经过四次上采样,上采样操作包含了卷积层和2$\times$双线性插值组成。最后得到输出密度图。
在这个阶段,损失计算的是预测人数和实际人数之间的损失(与预训练阶段不同)。
Mosaic图像增强
**为了解决长尾问题(重要的示例无法多次出现)**,所以提出了Mosaic图像增强,分为两个步骤,拼接和混合。
拼接
拼接是从图像中裁剪出正方形区域,然后统一大小后,拼接起来,同时更新对应的密度图。文章提到了两种不同的拼接方式,分别是使用四张图或一张图(根据这幅图像的点注释来判断),如果大于某个阈值,就用一张图,即将图像重复四次,否则使用四张图像,使用四张图像会用一张原图中裁剪出来的图像,其余从训练集中选择,如果类别一致就继续拼接,调整密度图,否则就只拼贴,密度图设置为全0。
混合
因为直接拼贴无法完美合成,所以会有一个混合宽度,就是用比拼接图像块固定尺寸稍微大一些,多出来的部分用于通道混合,使拼贴得到的图像更加逼真。
测试时归一化
在测试时,会使用测试时归一化。通过这种方法可以校准输出的密度图。
滑动窗口预测,如果边界框长宽都小于10像素,将会图像分成9块,每块是原图的九分之一,通过滑动窗口累计每个小块的计数和,计数和就是最终的计数结果。否则,直接利用滑动窗口预测。
源码理解
我对作者提供的代码中对FSC147数据集进行处理的内容以及模型文件做了注释。包括预训练、微调和测试部分。
具体内容可以看
https://github.com/LengNian/PaperRecurrent/tree/main/CounTR--Transformer-based Generalised Visual Counting(不要点链接,复制到浏览器)
参考文章
CounTR: Transformer-based Generalised Visual Counting - 郑之杰的个人网站
《CounTR: Transformer-based Generalised Visual Counting》CVPR2023-CSDN博客
