本文用于记录自己在学习Transformer中理解,方便日后复习,文章中所使用图片全部来自于参考文章中所列文章或视频,仅用于个人学习使用。
Self-attention
Personal understand
self-attention可以和fc交替使用,输入几个vector,就会输出几个vector。
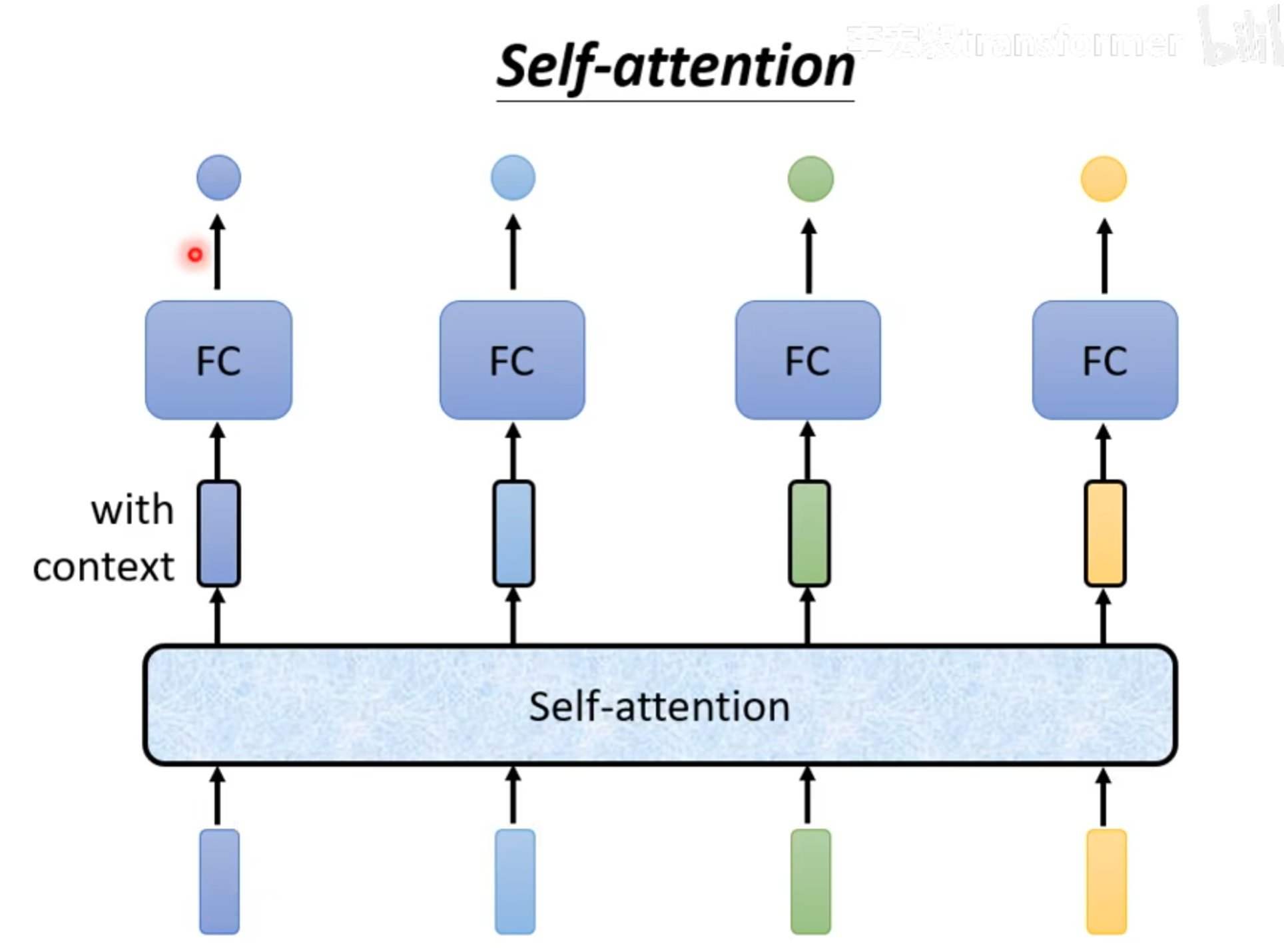
默认计算注意力的方法使用Dot-product
假设在a之前还有其它运算,所以命名为 $ a^1, a^2,…$。
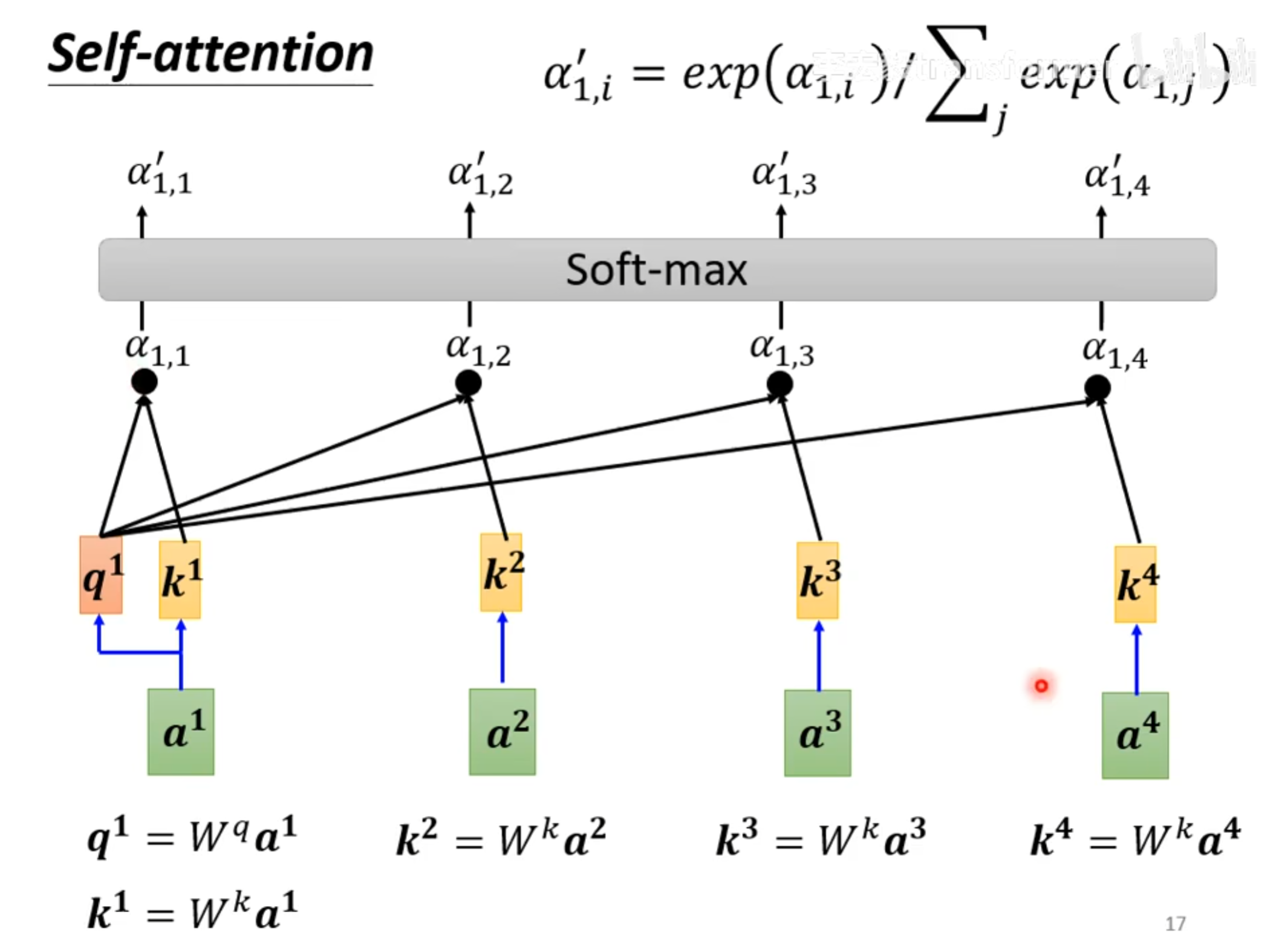
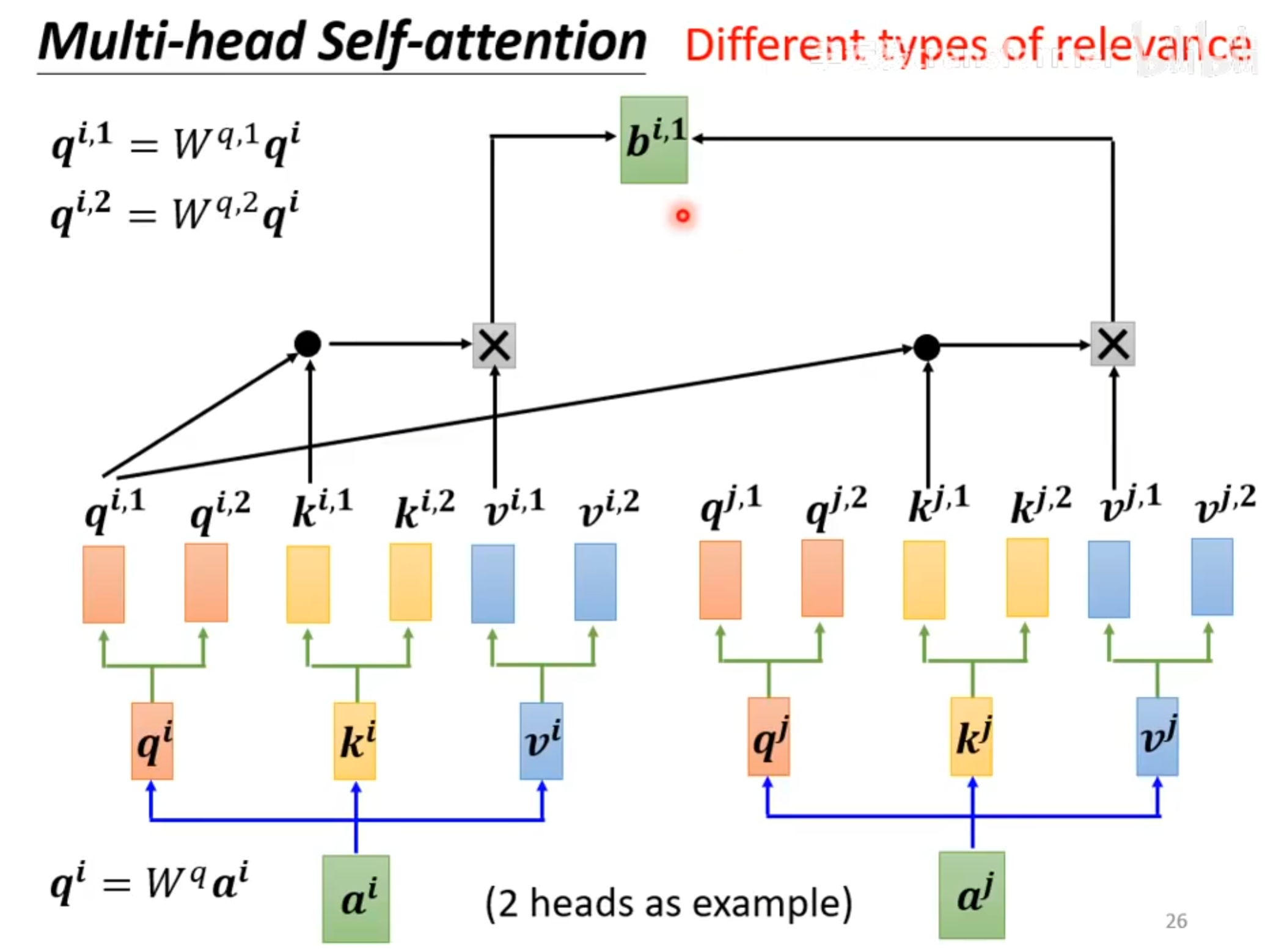
如图,query,key,value是如何产生的?
有一个$ W^q $矩阵,通过和输入$a^i$相乘,就能得到$q^i$,也就是query。
同理。也存在一个$W^k, W^v$矩阵,和输入$a^i$相乘,就得到 $k^i, k^v$,也就是key, value。
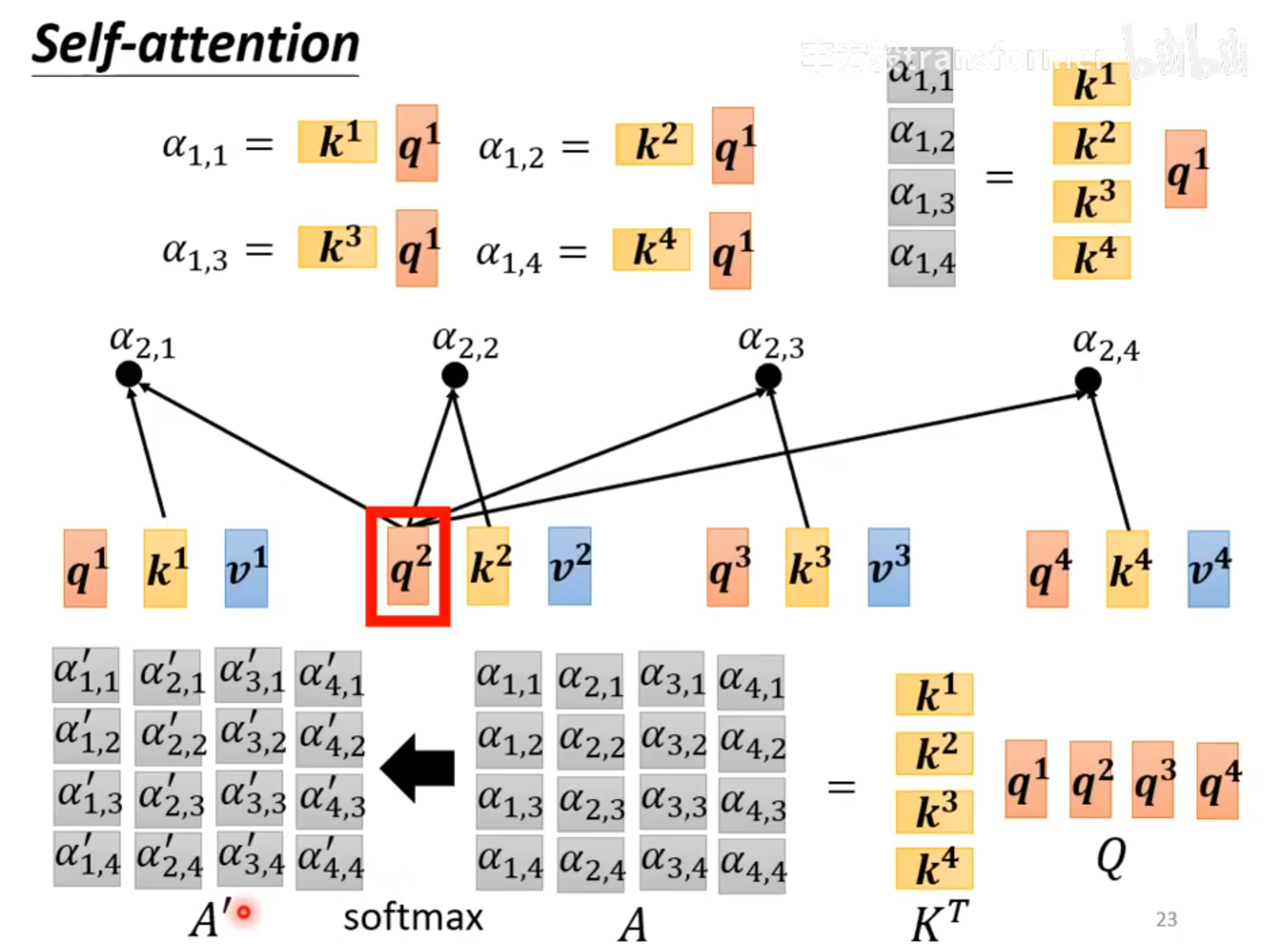
$query和key进行一个dot product就得到了注意力分数也就是图中所示的\alpha$
以$a^1$为例,$q^1$ dot product $k^1以后得到了\alpha_{1,1}, q^1和k^2得到了\alpha_{1,2}…$
**我的理解就是$\alpha_{1,j}$就是特征1和特征1、特诊2…特征j之间的注意力分数,为了更好运算,将这些进行一个softmax,统一到(0, 1)之间,得到了 **${\alpha _{1, j}}^{‘}$。
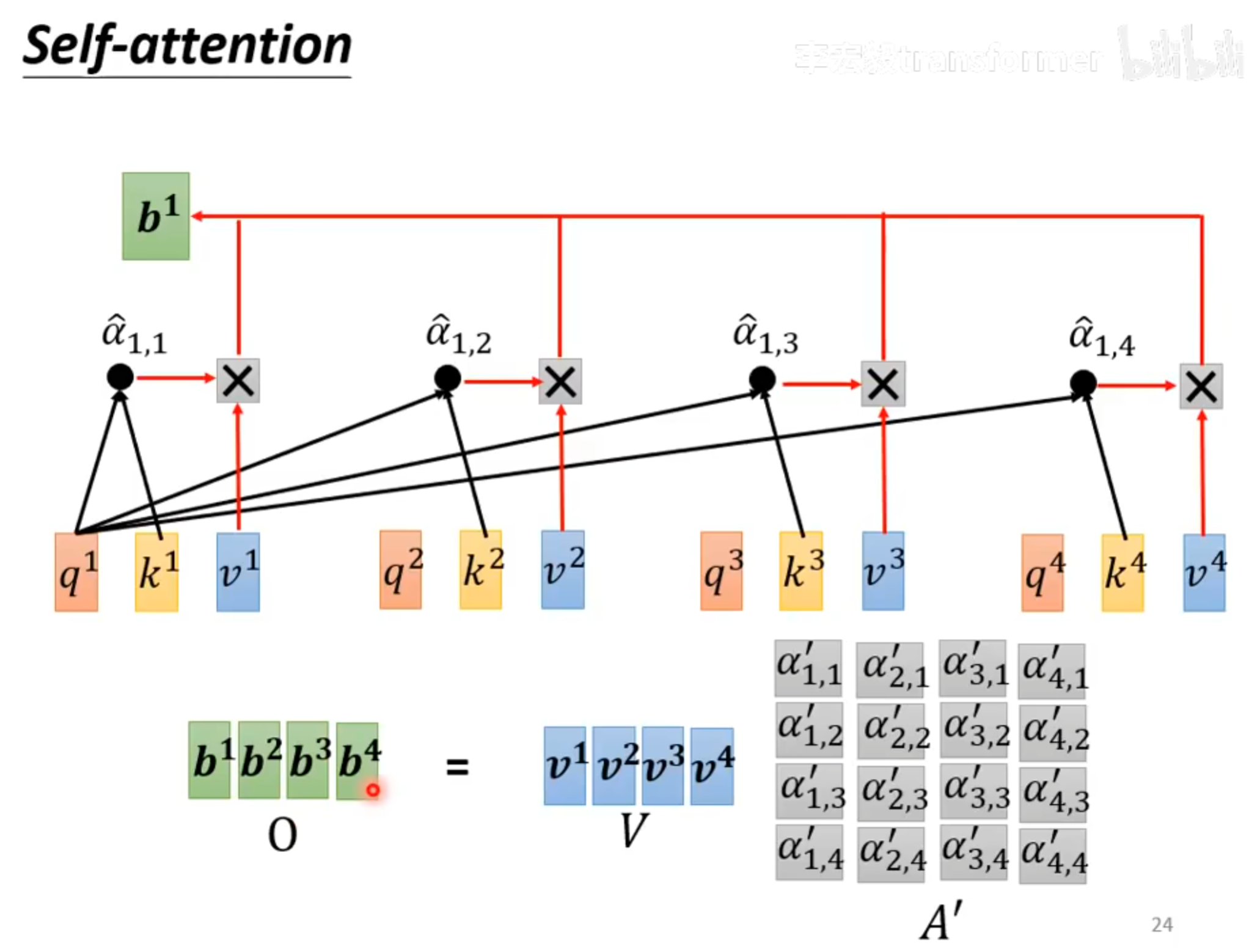
之后将$\alpha^{‘}_{1,j}和对应的v^j相乘,就得到了b^1$。
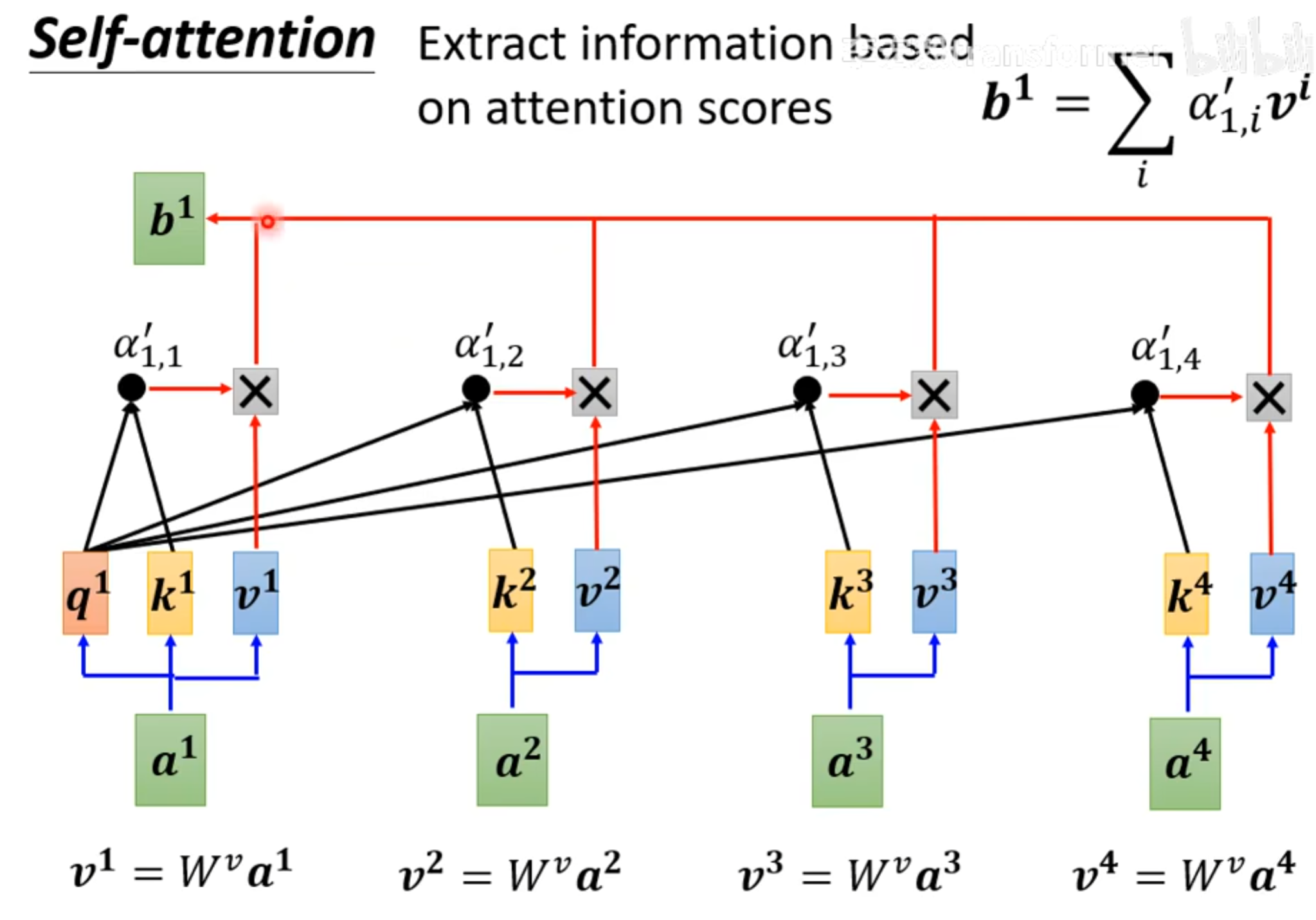
上面的两张图是对输入$a^1$进行计算的一个过程。其他的输入也一样。
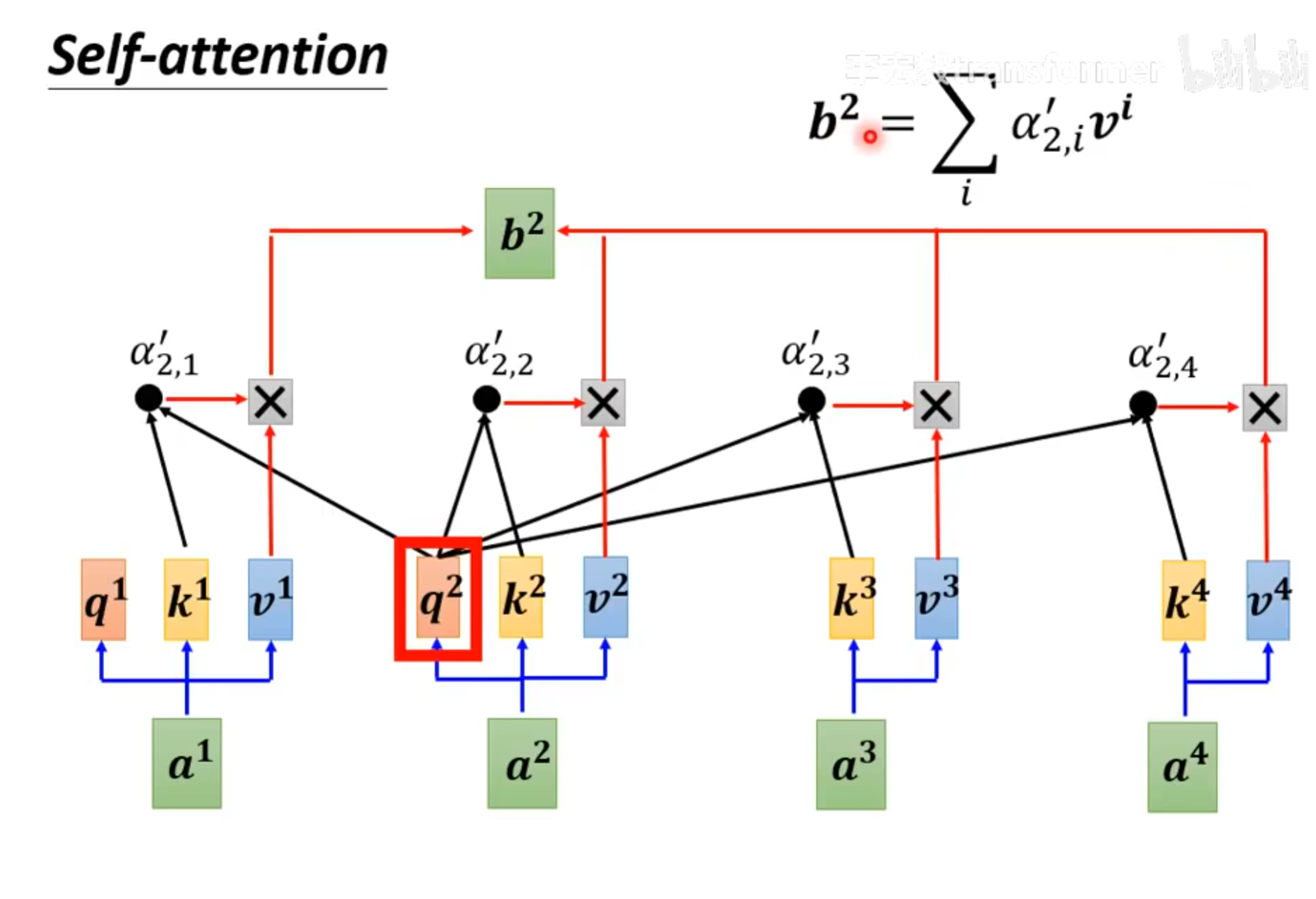
Matrix Multiply show
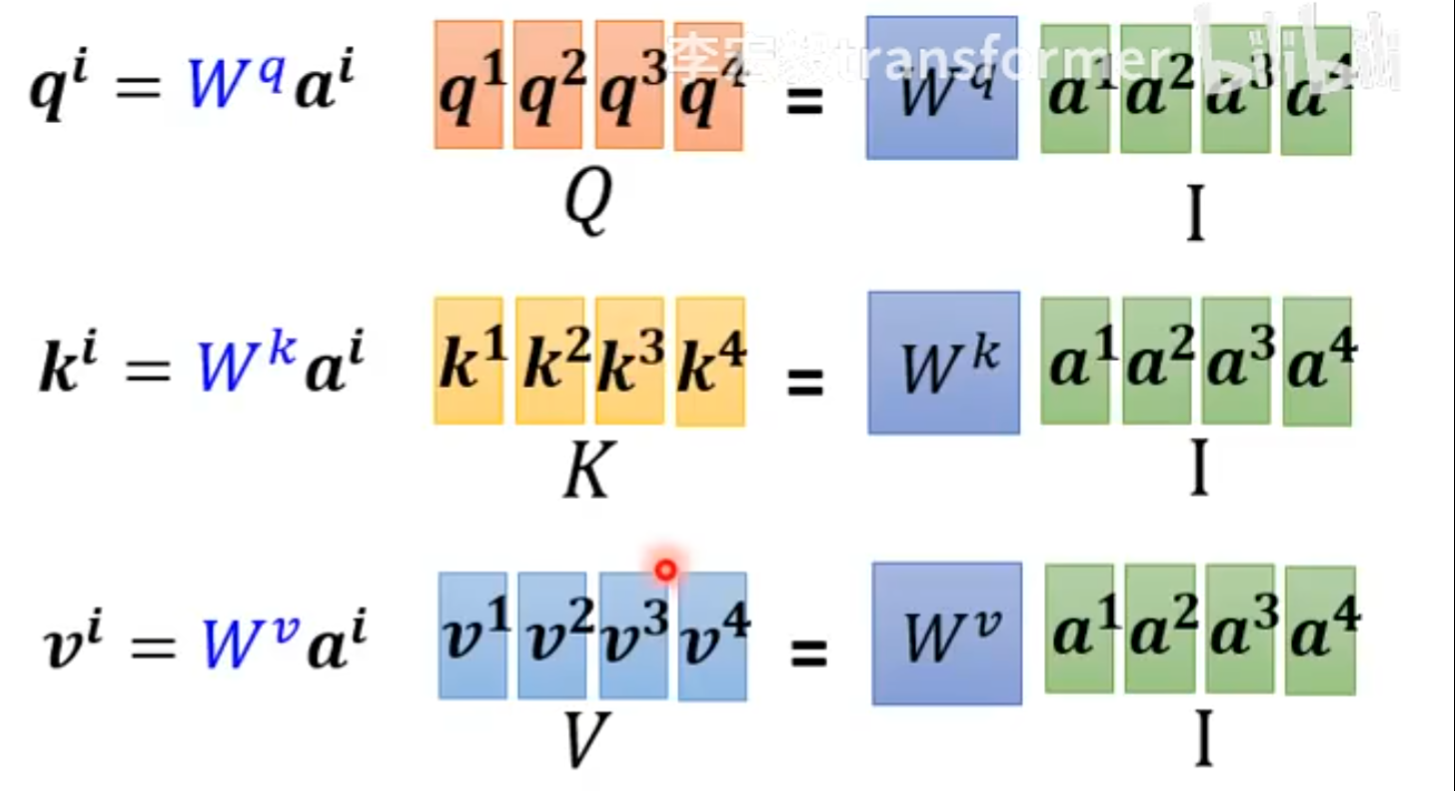
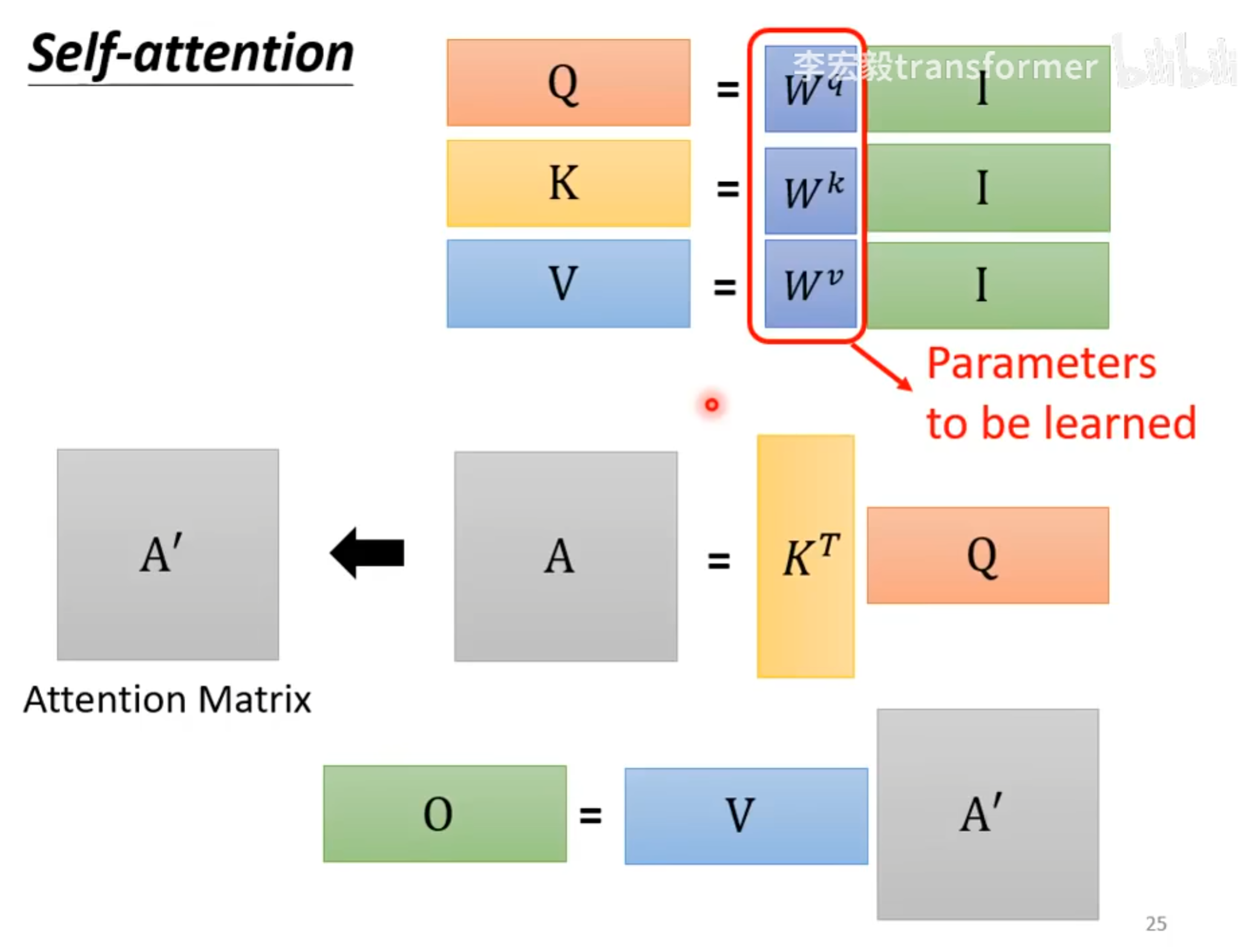
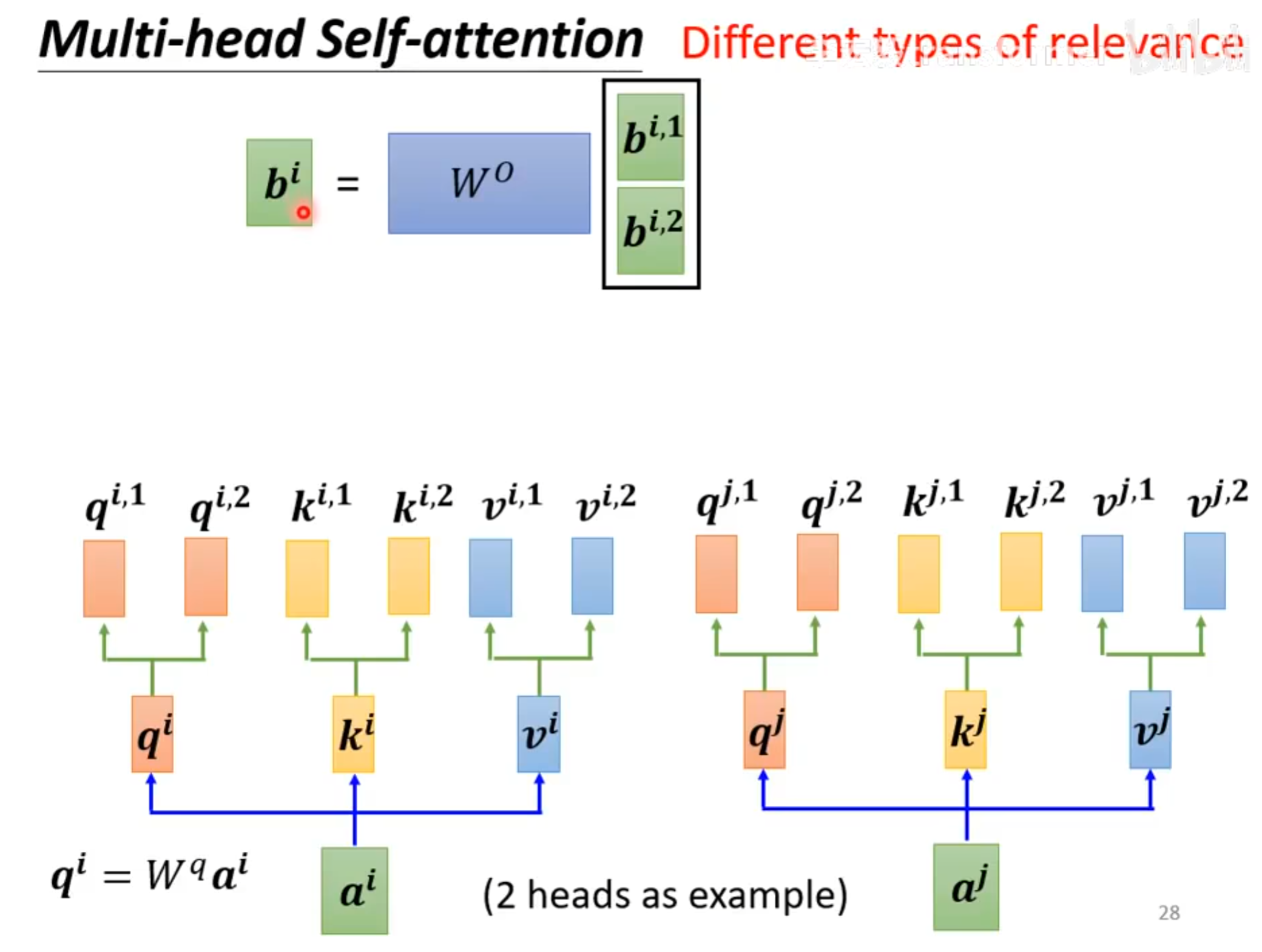
在整个self-attention过程中,只有 $W^k,W^v,W^q$ 是需要通过训练学习的。
Multi-head Self-attention
Positional Encoding
位置编码通过一种特殊的方式产生,不一定要通过sin/cos产生,也可以通过网络学习产生。
Compare
self-attention就是复杂的CNN
普通的RNN只考虑了左边最近的一个词,而且无法并行处理,而self-attention可以并行处理,并且考虑了所有词之间的关系。
Transformer
Encoder
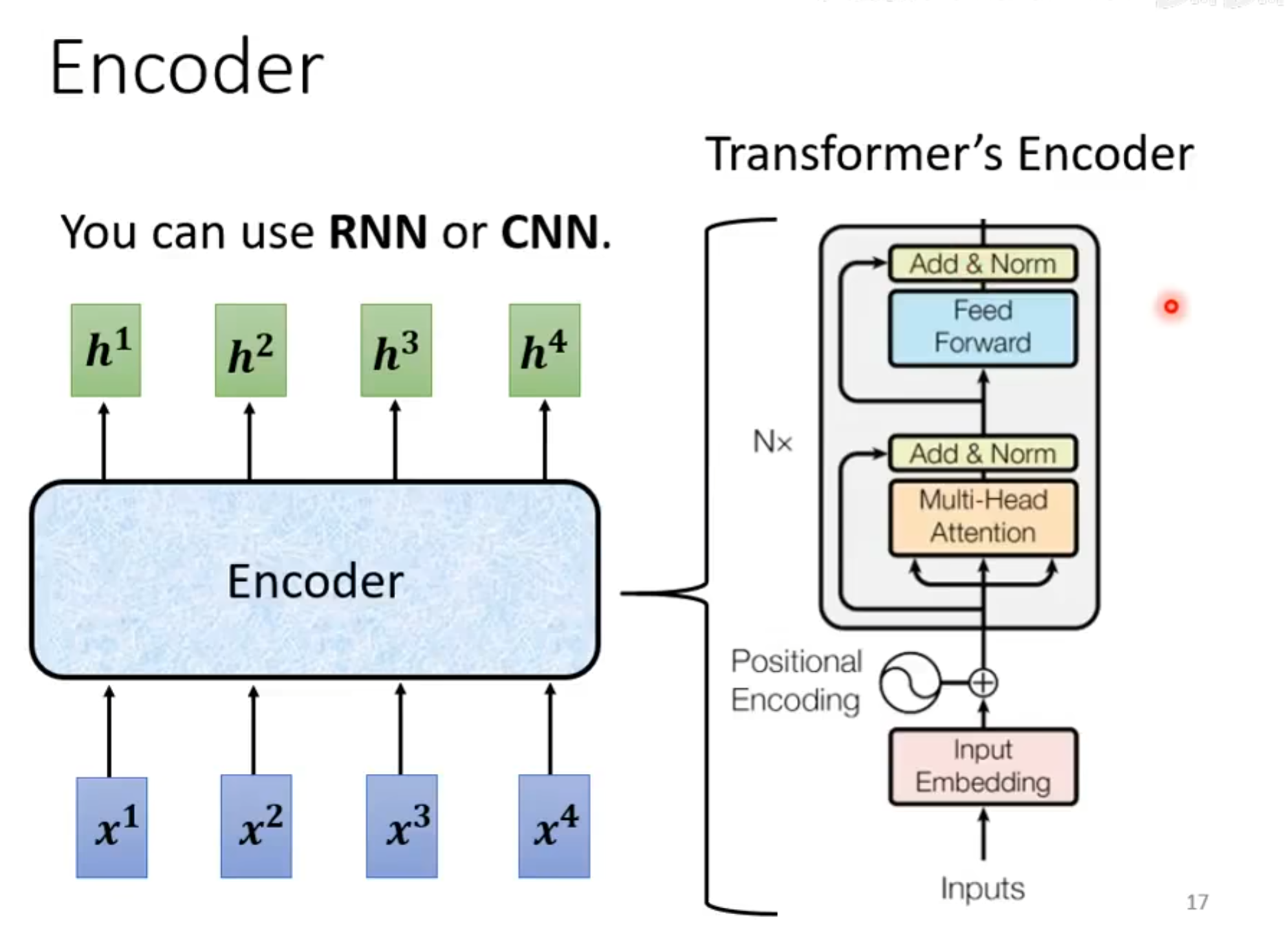
Encoder可以简化成这种结构 ,里面包含
residual connection
layer norm
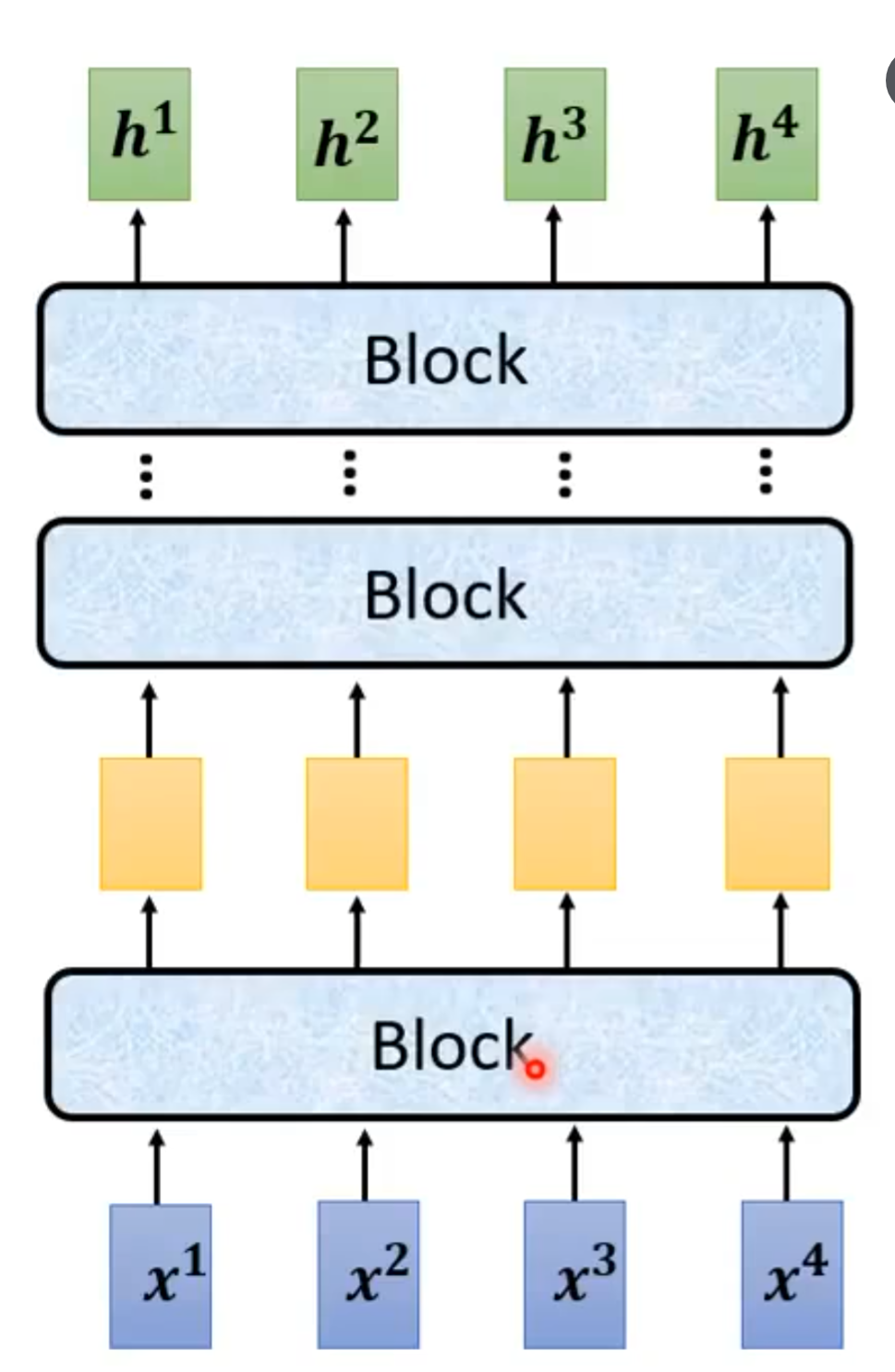
每个block的结构又如下图所示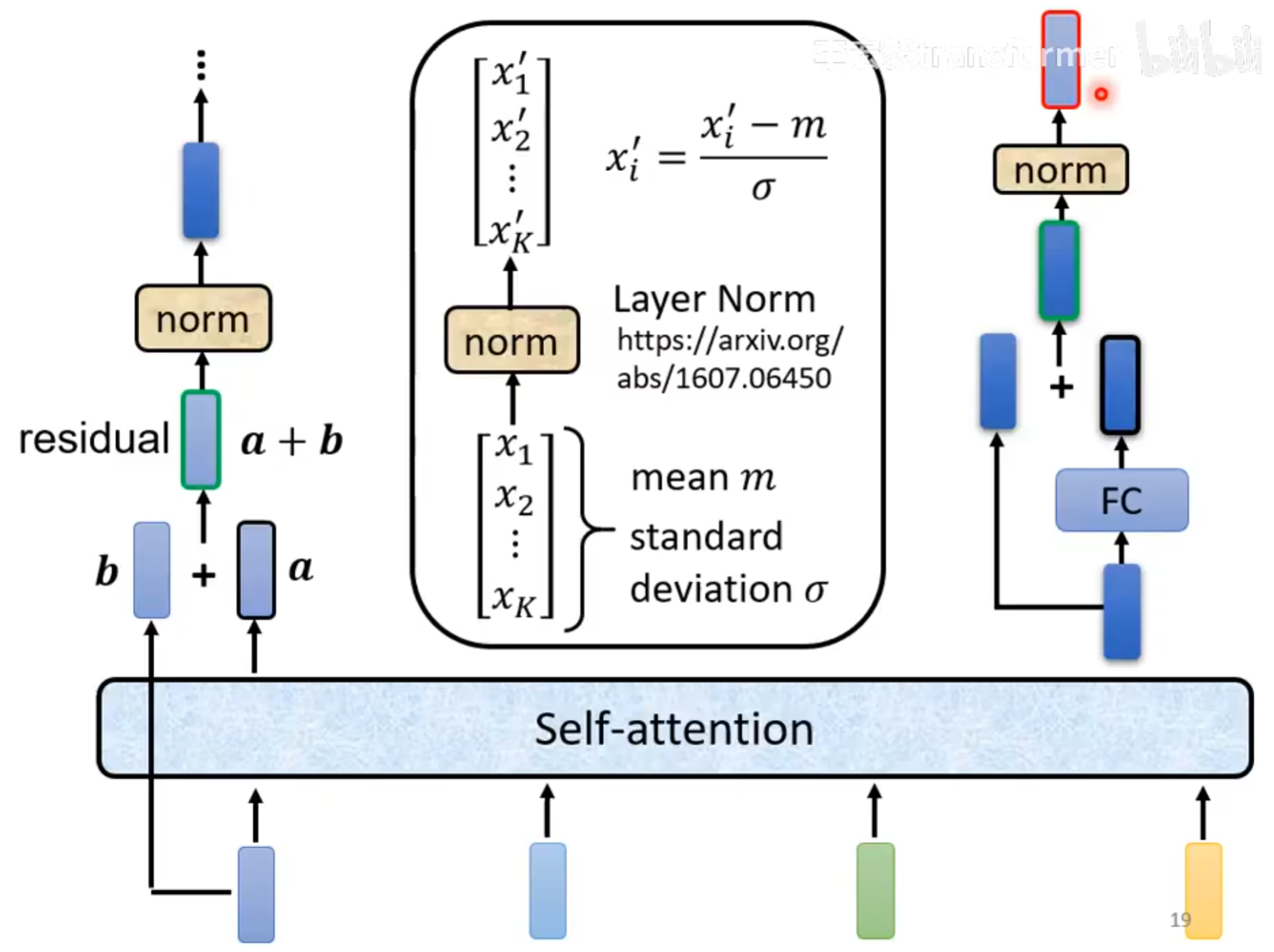
Decoder
Input & Output
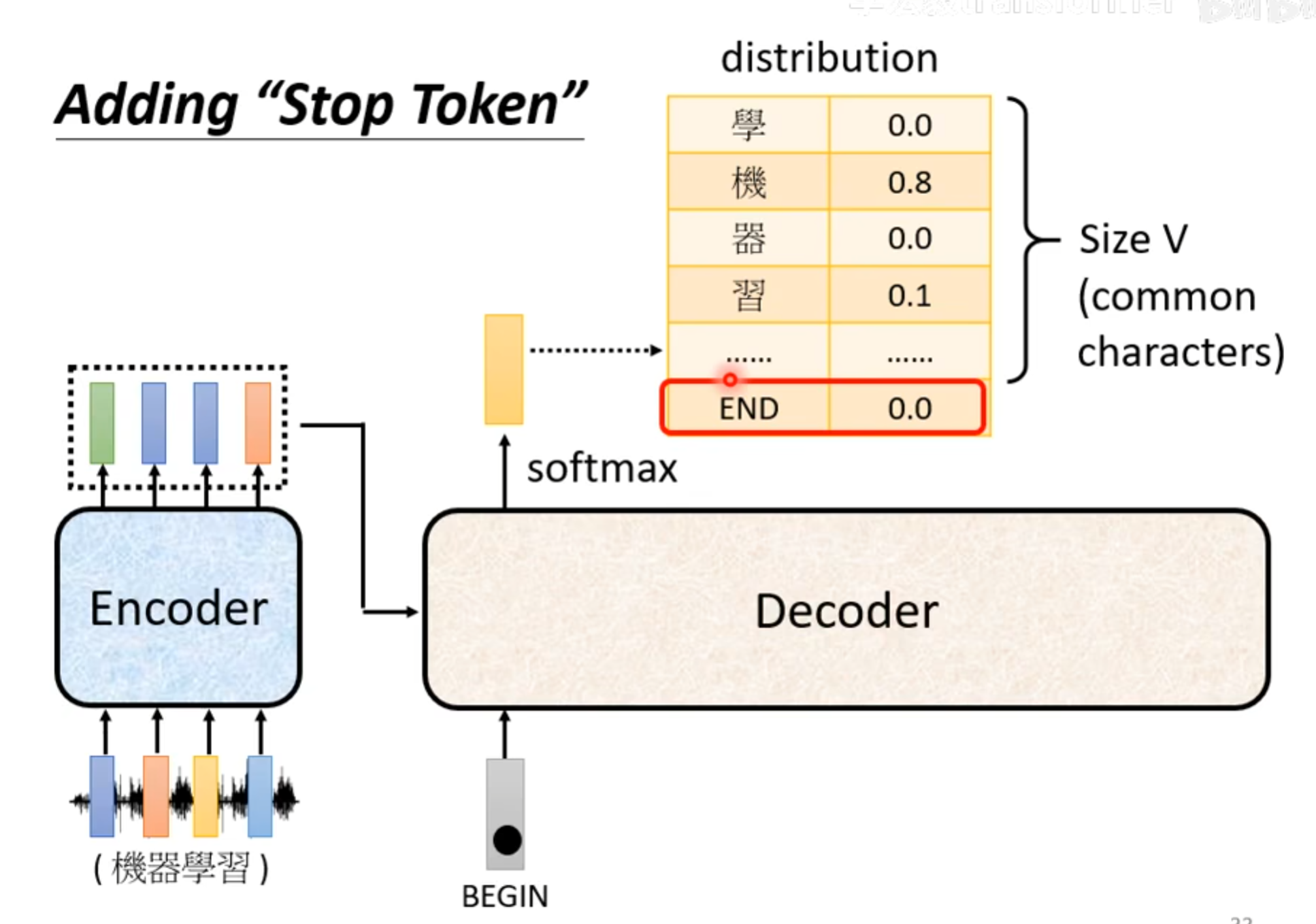
voc_size:就是可能输出的单词总数,比如26个字母,或者2000个汉字
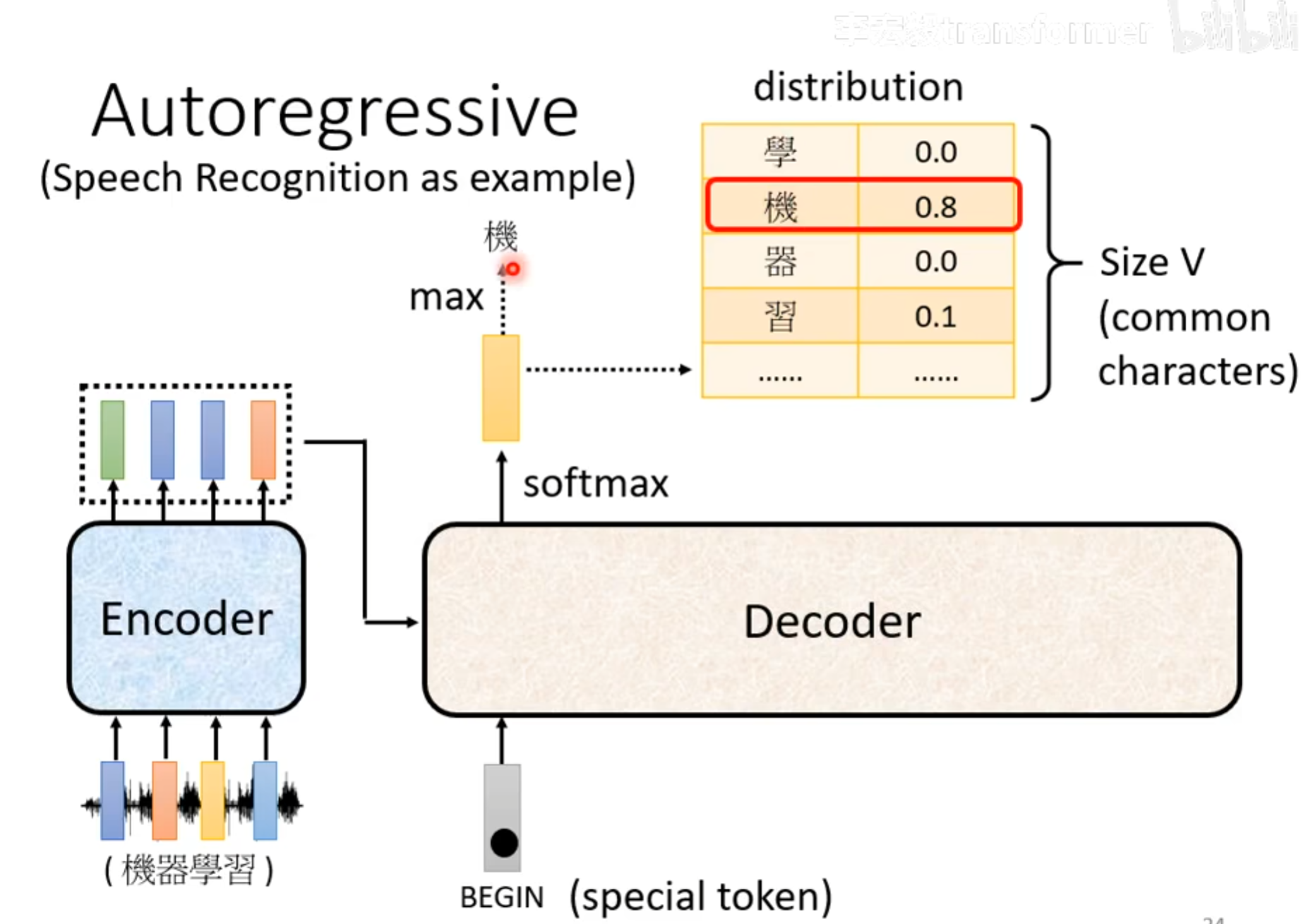
这里的distribution经过一个softmax,加起来的总和是1,选择一个概率最大的,作为decoder的下一个输入,Decoder看到的输入其实就是自己上一次的输出,所以是可能看到错误的。
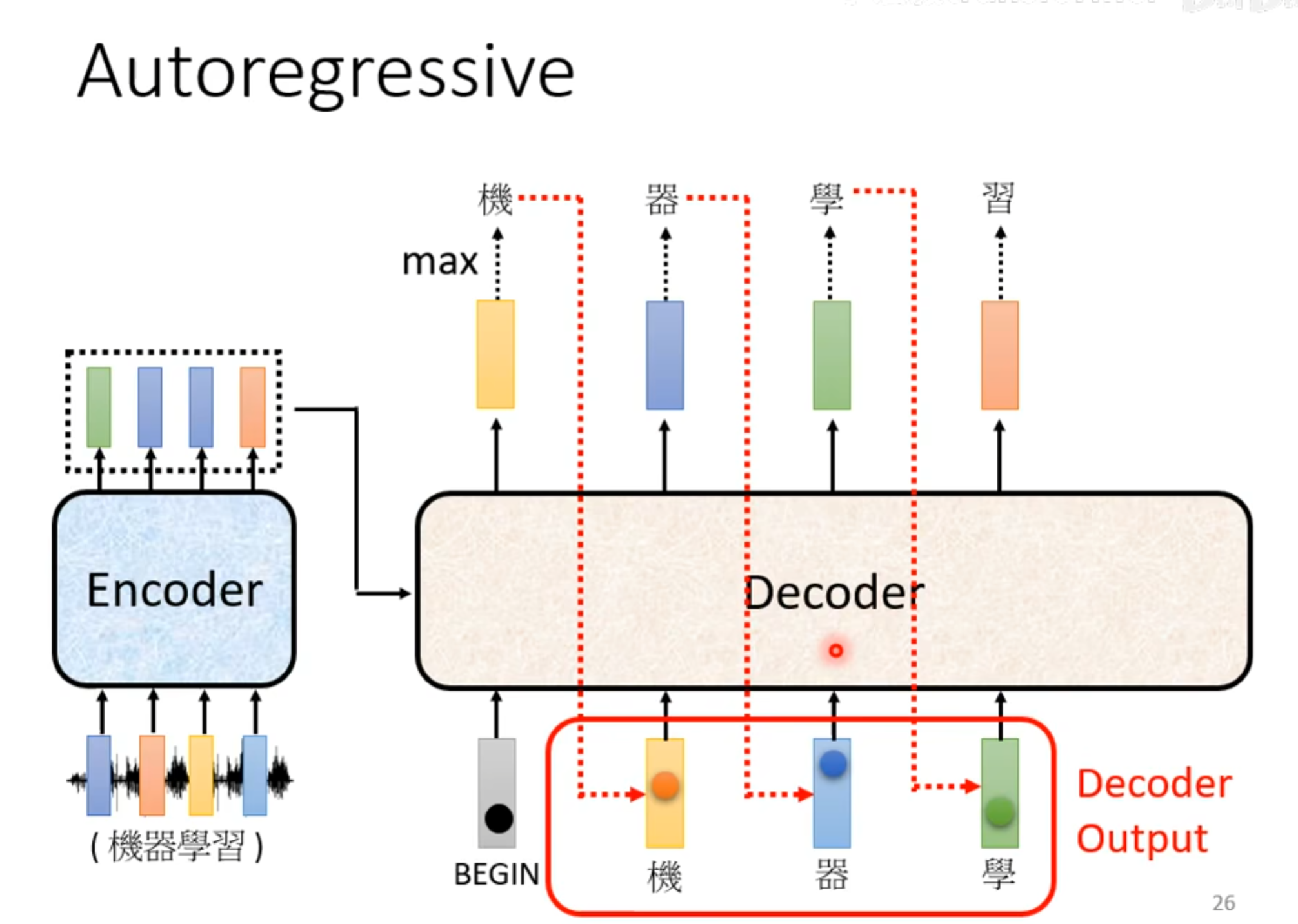
Masked multi-head-attention
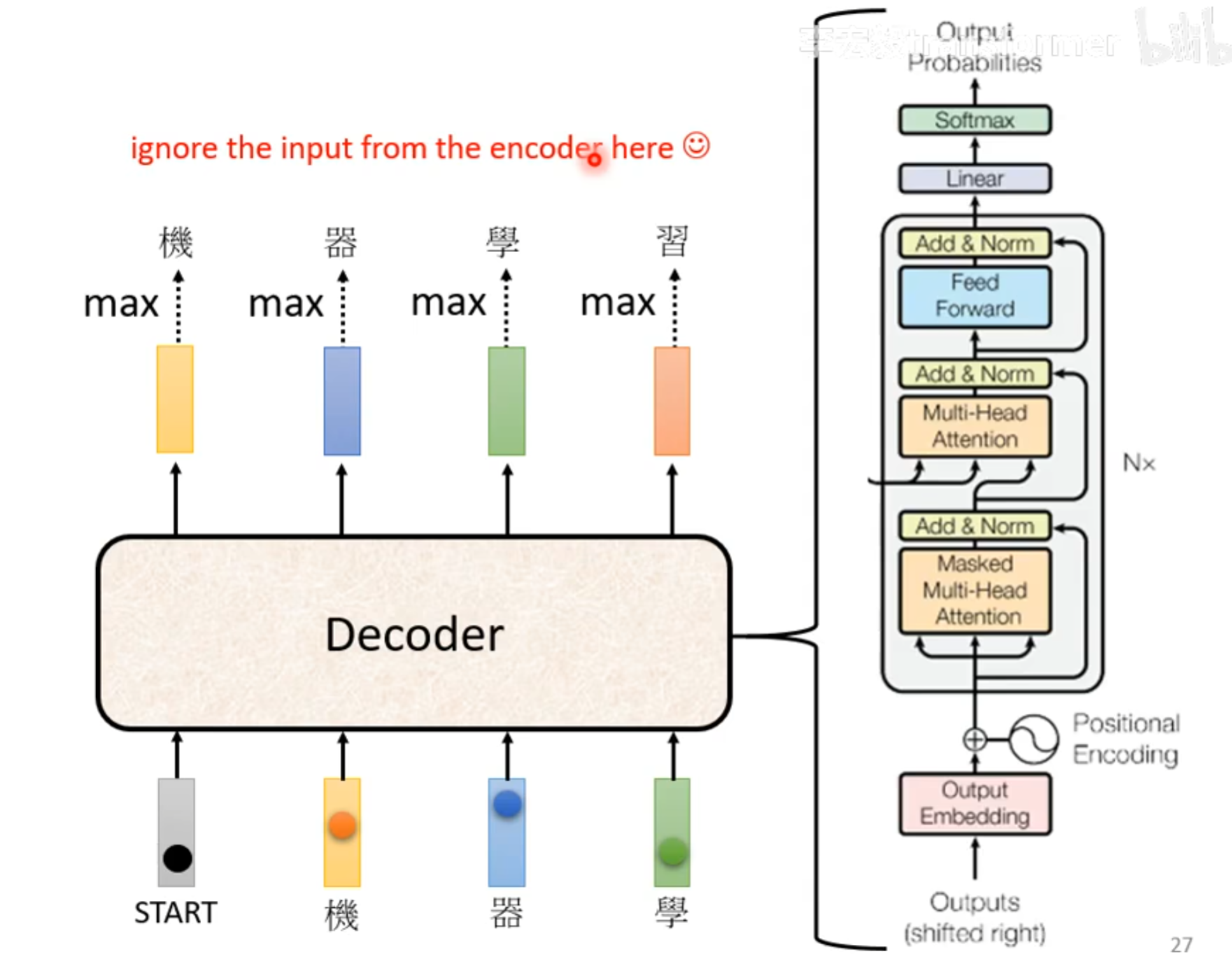
可以注意到Decoder中有一个Masked Multi-Head Attention,这里的masked的意思就是看不到在输入之后的内容
比如处理 $a^1$时,只能和$a^1自己计算得到b^1$,处理$a^2时,只能和a^1,a^2进行计算得到b^2,在处理a^4时,则是和a^1,a^2,a^3,a^4进行计算得到b^4$。
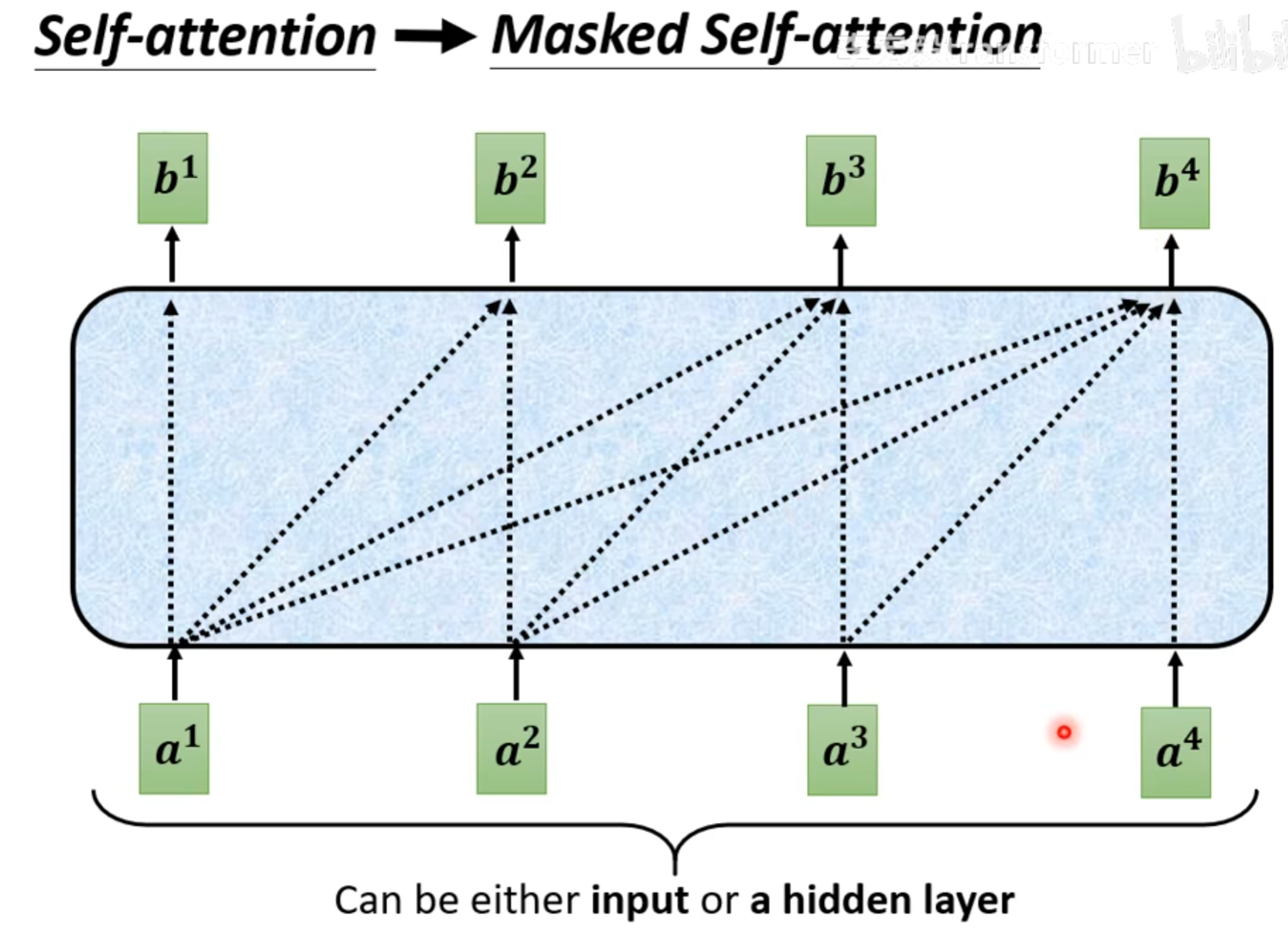
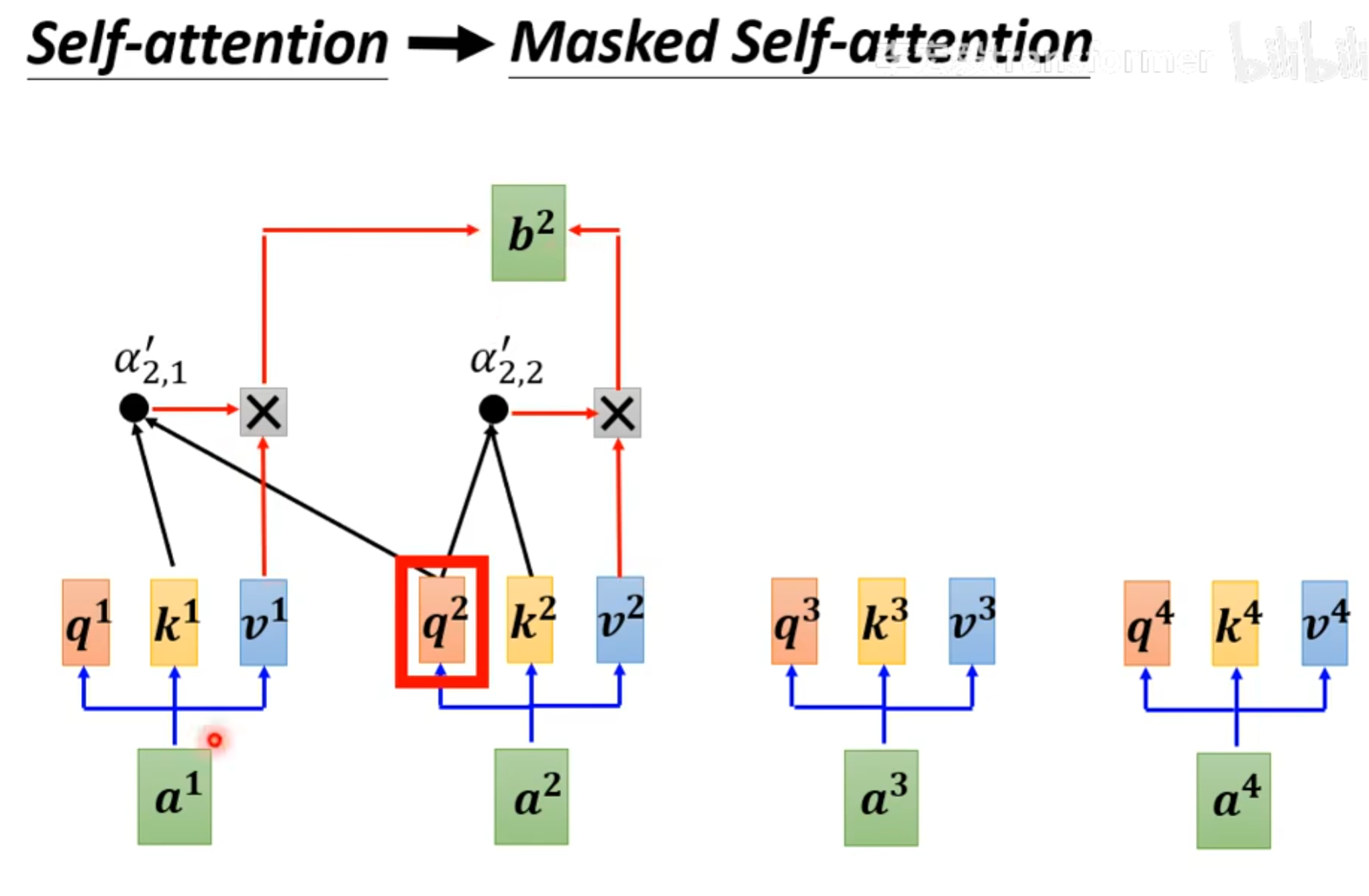
为什么要用masked?
本文刚开始提到的self-attention的输入是一次性给进去的,所以计算注意力时可以使用后面的,而transformer中的输出其实是一步一步产生,也就是处理$a1$时,并不知道$a^2$的值,处理$a^2时,只能用a^2,a^1,而并不知道a^3,a^4$。所以这里就要用masked。
这里要有特殊符号,BEGIN和END,用于开始开始和结束。
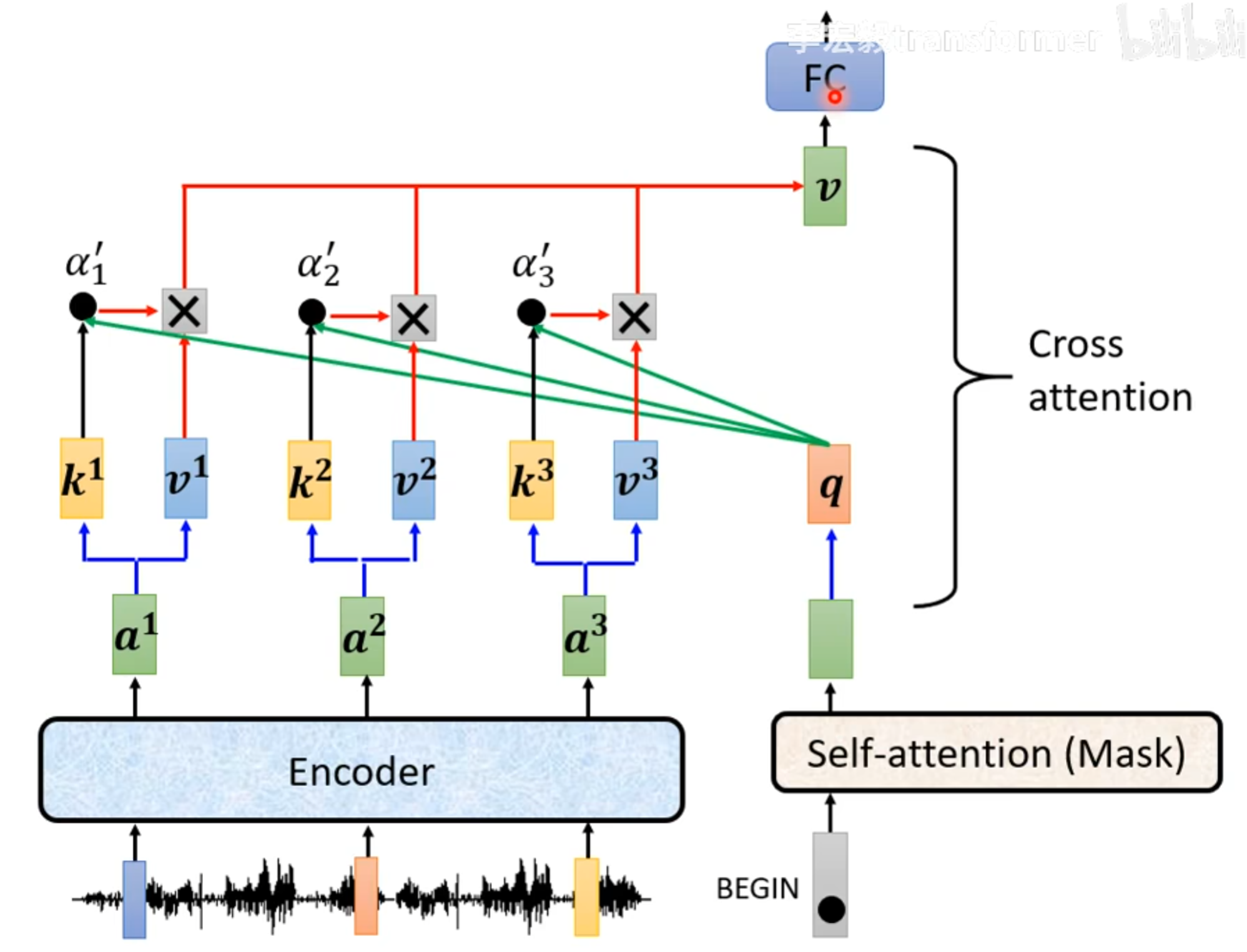
Cross attention
Decoder提供一个query,Encoder提供key和value,使用q和k计算注意力分数以后,再和c相乘,就是交叉注意力机制的过程。
Training
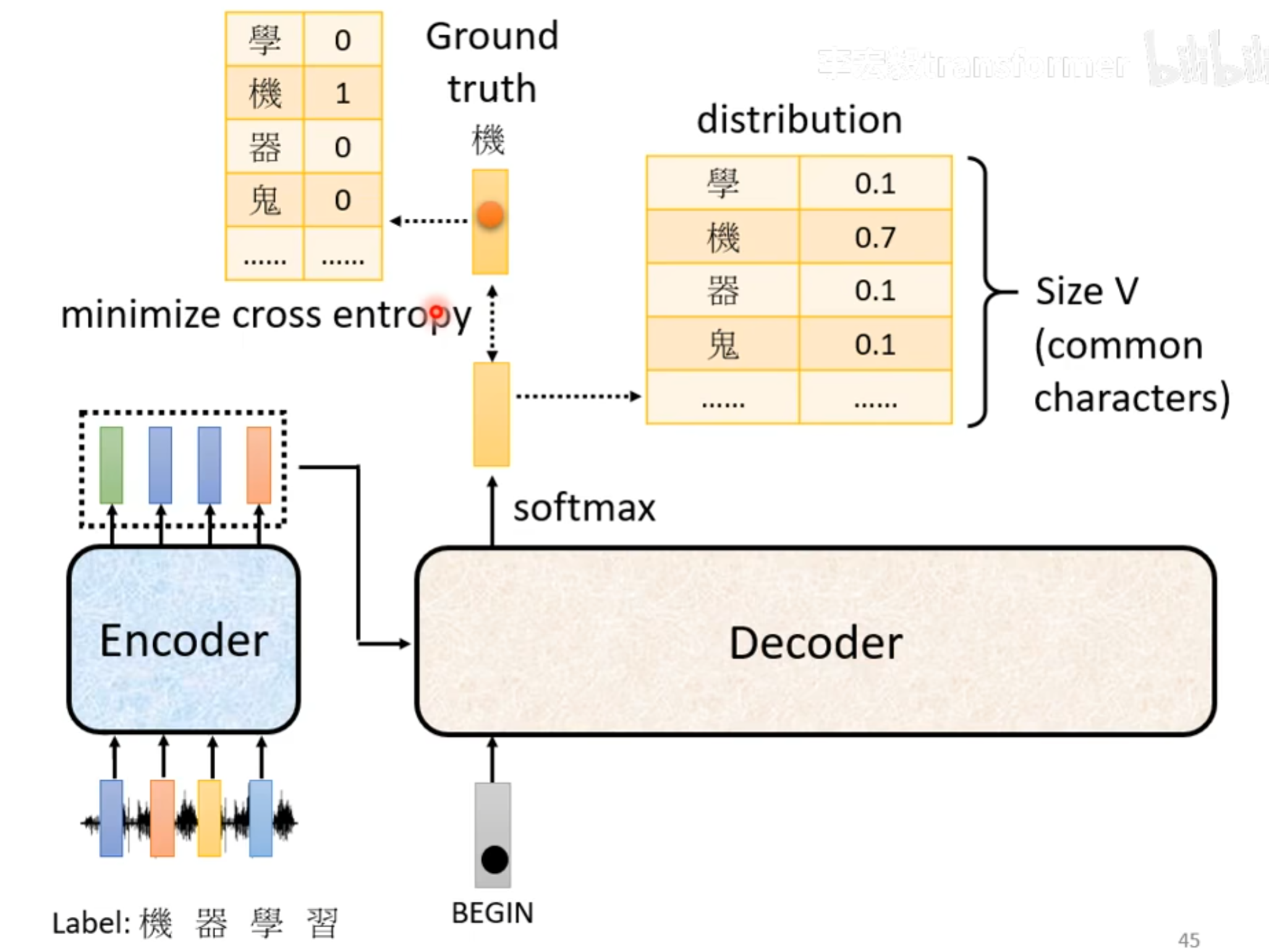
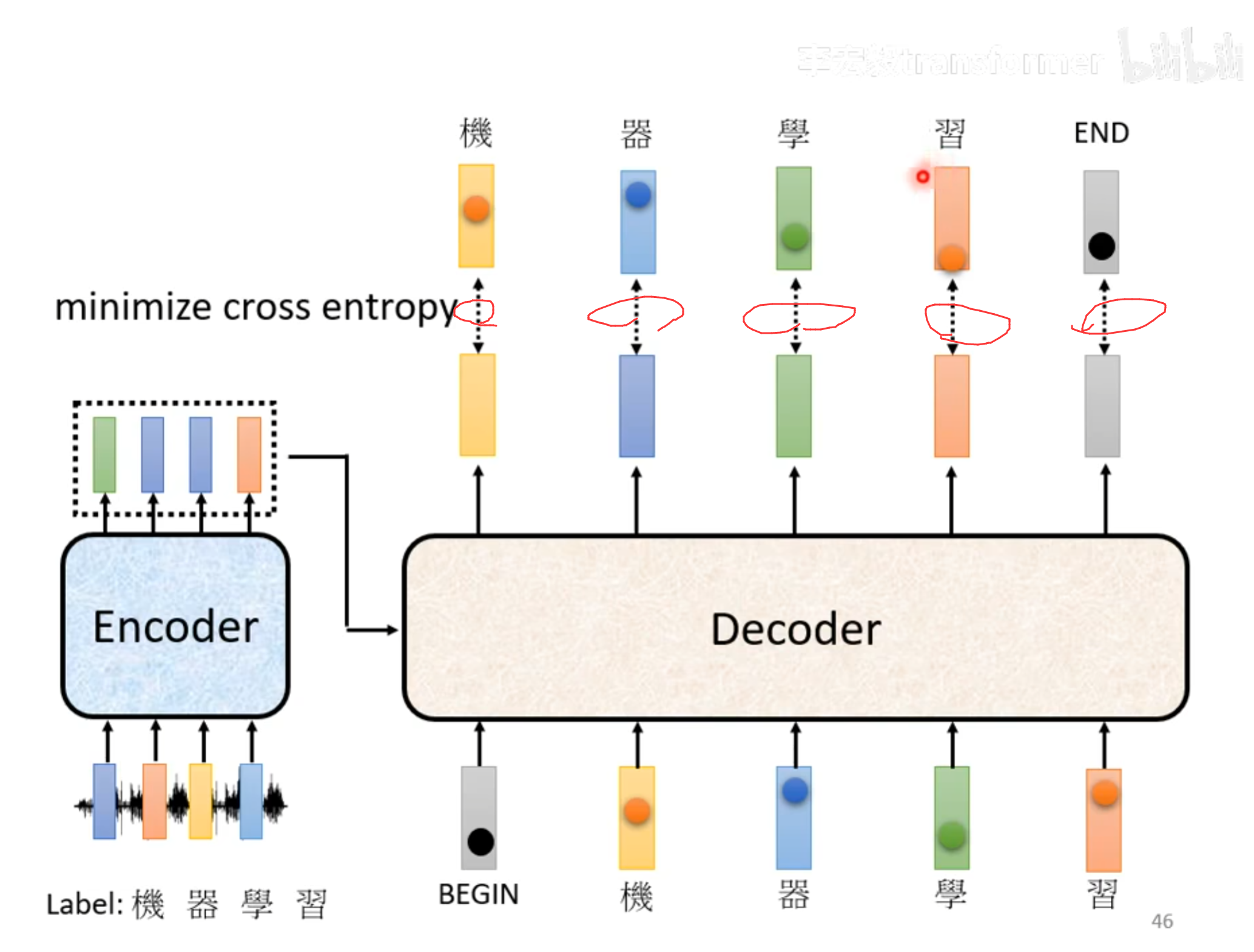
Decoder每一个输出都有一个cross entropy,希望cross entropy的总和最少,同时模型还要能够输出结束标记END。
参考文章(视频)
【研1基本功 (真的很简单)注意力机制】手写多头注意力机制_哔哩哔哩_bilibili
Transformer终于有拿得出手得教程了! 台大李宏毅自注意力机制和Transformer详解!通俗易懂,草履虫都学的会!_哔哩哔哩_bilibili
【官方双语】GPT是什么?直观解释Transformer | 深度学习第5章_哔哩哔哩_bilibili
从编解码和词嵌入开始,一步一步理解Transformer,注意力机制(Attention)的本质是卷积神经网络(CNN)_哔哩哔哩_bilibili
