本文用于记录自己在学习Vision Transformer中理解,方便日后复习,文章中所使用图片全部来自于参考文章中所列文章或视频,仅用于个人学习使用。
Vision Transformer
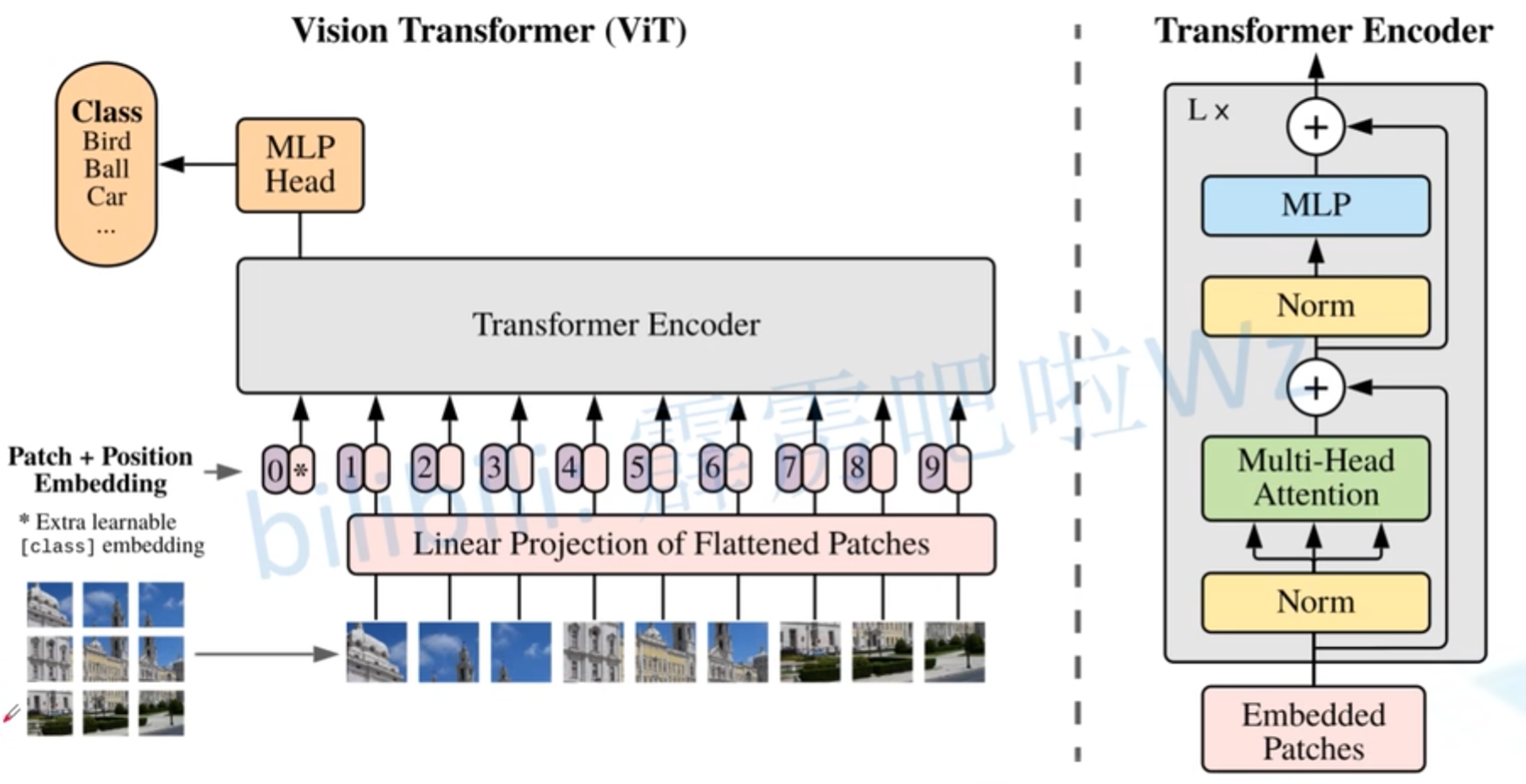
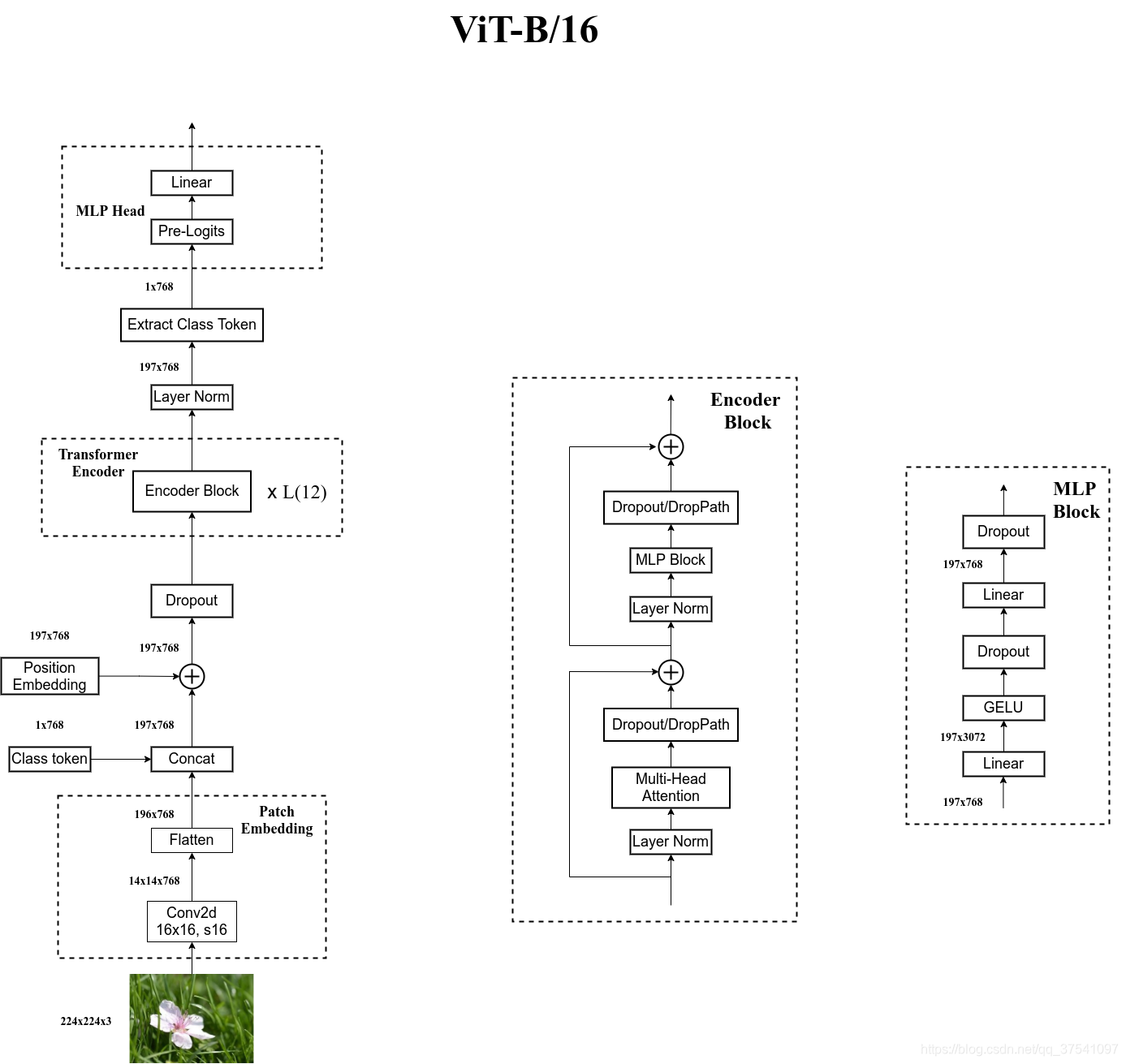
这里的输入把图像分成大小为16*16的patch,然后将每个patch输入到Linear Projection of Flattened Patches(Embedding层),就能得到token。在这些token之前会再增加一个class token,并且加入位置编码Position Embedding。再输入到Transformer Encoder中,最后用MLP Head进行分类。
Embedding层
对于标准的Transformer模块,输入应该是token序列,[num_token, token_dim]。
实际操作中,Linear Projection of Flattened Patches是直接通过一个卷积层来实现的。,以ViT-B/16为例,使用卷积核大小为16*16,stride为16,卷积核个数为768,这里的768就是token_dim。
图像尺寸的变化就是[224, 224, 3] –> [14, 14, 768] –> [196, 768],先通过卷积层,再把长宽摊平。(14 = 224/16, 196=14*14)
在输入到Transformer Encoder之前需要加上class token以及position Embedding(这些都是可训练参数)
拼接class token: Cat([1, 768], [196, 768]) –> ([197, 768])
叠加Position Embedding: [197, 768] -> [197, 768] (加数值,所以维度没有发生变化)
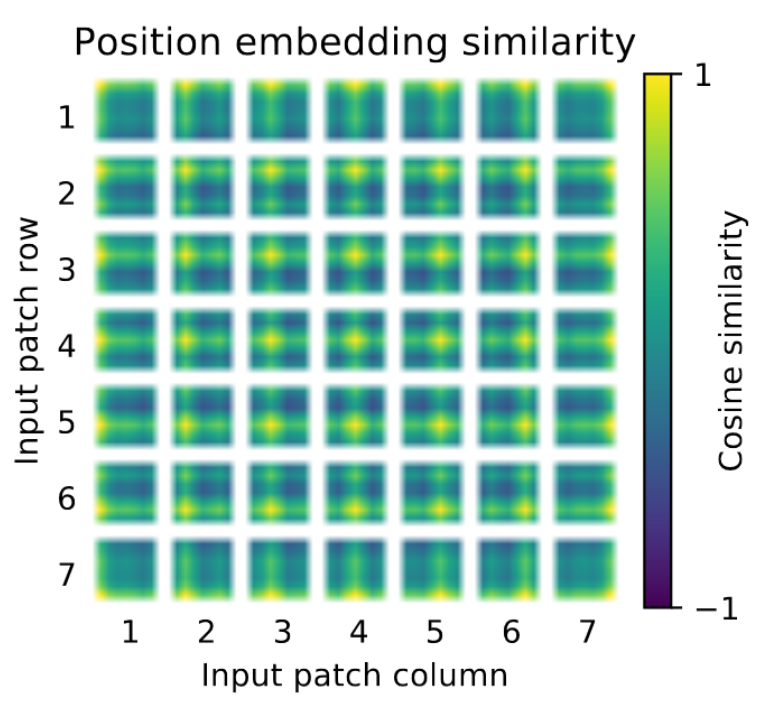
位置编码的余弦相似度:
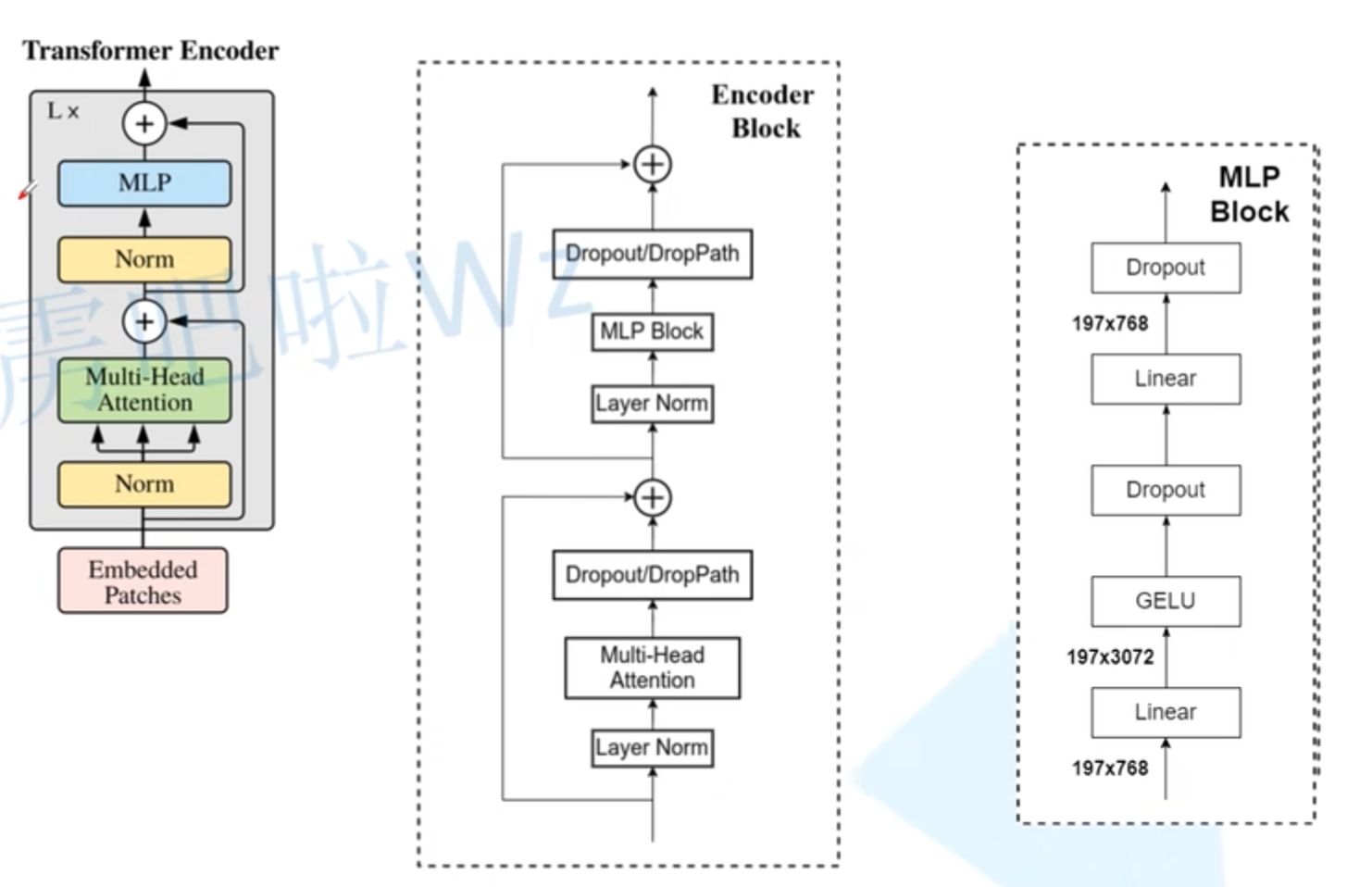
Transformer Encoder
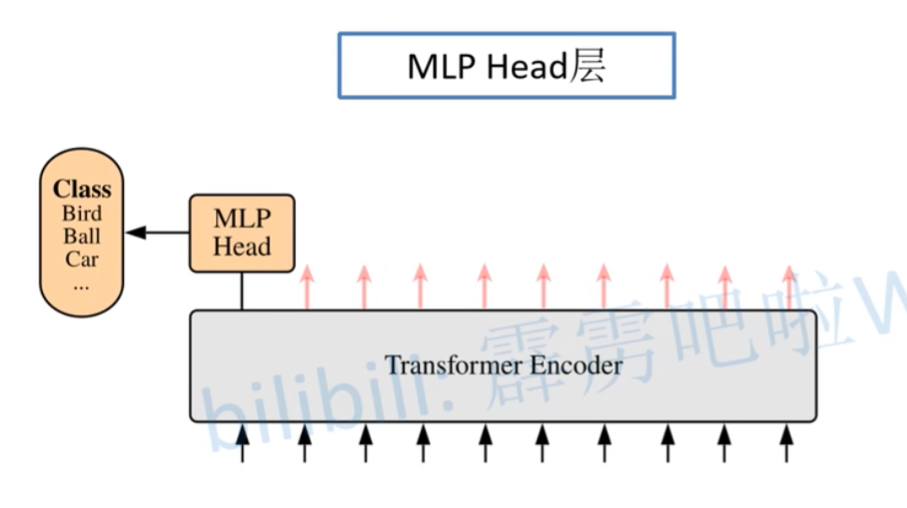
MLP Head
MLP Head可以简单理解为就是一个Linear层。
ViT-B/16结构
参考文章(视频)
11.1 Vision Transformer(vit)网络详解_哔哩哔哩_bilibili
11.2 使用pytorch搭建Vision Transformer(vit)模型_哔哩哔哩_bilibili
狗都能看懂的Vision Transformer的讲解和代码实现_vision transformer代码-CSDN博客
